WORDFAST CLASSIC
DOCUMENTATION
Version 9.xx ~ All rights reserved
Ⓒ 1999-Now, Yves Champollion
|
WORDFAST CLASSIC |
Wordfast Classic (WFC) is a Computer-Aided Translation (CAT) program designed as a Microsoft Word™ (thereafter written Ms-Word) add-on. Its primary purpose is to assist professional translators dealing with Ms-Word documents. WFC combines three core technologies: Segmentation, Translation Memory (TM), Terminology Recognition (TR). The reader who is not familiar with these concepts can read Appendix I for an overview.
WFC offers advanced terminology functions: three simultaneous glossaries, concordance search in unlimited numbers of TMs, reference search in various documents formats, links to various terminology databases, etc. The client's critical terminology can easily be entered in a WFC glossary, usually by copy-pasting; all segments will be checked for terminology consistency during the translation process.
WFC includes real-time Quality Assurance functions that include a typography checker, a terminology compliance checker, etc. Documents can be verified in batch mode so that project managers can have a detailed report on the typography/terminology quality of the documents they receive after translation.
WFC's TM format is open - it can be viewed or edited with Ms-Word™, Excel™, Access™ and many other popular programs. Furthermore, WFC ran read from or write into the TMX format used by other translation tools like TWB (Trados Translator's Workbench™), DéjàVu™, Star Star Transit™, SDL Suite™, MemoQ™, etc.
All this power is packed into a compact Ms-Word template, for Ms-Word versions 2000 to 2016, as well as Ms-Word for Mac 2019. An unlimited number of users can share the same translation memory and/or background memory over a local area network. WFC can also be linked to a Machine translation (MT) program or server (locally or through a network) to provide MT when no match is found in the TM.
Translation managers can develop project-specific extensions to meet specific requirements thanks to Ms-Office's programming platform (VBA) used by WFC.
Our hope is that this tool will help you increase productivity and provide a better work environment.
The Wordfast Team
www.wordfast.net
If you start using WFC, take time to get acquainted with it before engaging in large or complex projects. Make sure you test WFC on your system and are aware of its limitations. Not all projects or documents can be translated with WFC. There is a level of document complexity (layout, formatting, embedded objects, dynamic documents linked to sophisticated templates, documents with very large tables, etc.) beyond which WFC, and most CAT tools, will give up. Ms-Word documents that are formatted to mimick other application like Excel or PowerPoint by using many textboxes or tables, will be more difficult to handle, although an expert and careful user can succeed. Those include PDF conversions, OCRed material, documents that contain numerous textboxes, forms and input fields, so-called "Wordart" shapes, callouts, etc.
After translation, review your layout, as elements anchored to text will move with the translated text's new position.For formats that are not Ms-Word DOC(X), please consider Wordfast PRO, or Wordfast Anywhere. Translating so-called <tagged> documents remains possible, but requires expertise.
Very large or complex documents with over 100 pages of text can be prepared for translation, for example, by splitting them into smaller, more manageable sub-documents, removing large graphics, etc.
When you consider starting a translation project where there are formats or layouts you have not handled before, test-drive WFC on sample paragraphs to make sure it will behave correctly before accepting the job. Proceed with caution when there are technicalities you are not comfortable with.
WFC does not replace the translator's ability to handle documents. Like all tools, WFC requires skills - it does not replace them.
The WFC website (www.wordfast.net) download page has training guides that are illustrated, step-by-step methods for beginners. Do not attempt to use WFC unless you learned the basics with the training guide level 1. The short instructions for use further below assume you're already comfortable with basic Ms-Word operation.
As with most electronic documents, you can quickly find information in this manual's 100+ pages using the standard Ctrl+F (Find) shortcut.
This is why printing the manual is not a good idea: you will find information in an electronic document much faster than flipping through a hundred pages. And this manual is constantly maintained up-to-date, as opposed to paper versions.
We are reluctant to answer hotline calls if the answer is easily and obviously found in the manual, or if the problem is strictly related to the use of the Operating System and/or Ms-Word rather than WFC.
Wordfast Classic's model is an End User License Agreement.
Essentially, the EULA is a right for users to download, install, maintain, and use the software for their own needs.
The licensing period runs for three years,
and comprises full use of all features for any number of documents, in any number of language combinations, with databases (Translation Memories, Terminology, etc.) of any size.
Users can move ("migrate") their installation of Wordfast Classic to other computers.
Individual users, such as freelance translators, can have up to two installations active at any time on two computers they both own and use.
Corporations can have one installation active on one computer that the corporation owns and uses.
Unlimited hotline and support is included in the license price, for the duration of the license.
Unlimited upgrades to new versions are also included.
After the initial 3-year period, the licensing period can be renewed for another three years at half the list price at the time of renewal.
Prices are listed at www.wordfast.com/buy
Size: up to 1,000,000 Translation Units (TU) per single TM. A TM is a simple Text file. You can create as many TMs as you want, in as many languages as you want, then enable/disable them as required. Note that two TMs can be used simultaneously: the main TM in read-write mode, and a Background TM (BTM), in read-only mode. WFC offers a tool called the Data Editor to create, split, merge, join, edit, maintain TMs.
Format: WFC uses TMs in either plain text format (ANSI), or Unicode text format (UTF-16 only, on Mac or PC). The Unicode format is the default, and preferred, format. The WFC TM format is open, straightforward, easy to read, maintain, share, and store. It is fully described in this manual in the WFC TM format section. Most text editors (the diminutive but powerful Notepad in Windows, or TextEdit in Mac OSX) can open a WFC TM for viewing, editing, merging, proof-reading etc. Ms-Word can be used to manage TMs, but WFC itself offers tools to edit TMs.
This format guarantees robust data, superior versatility and compatibility. It is probably the most compact format in the industry: a WFC TM is typically three to four times less bulky than its competitors. This is important when vast collections of TMs are considered.
The WFC TM format has never changed: WFC versions 1, 2, 3, 4, 5, 6, 7, 8 etc. all share the same format, while other TM solution editors keep changing their formats, regularly breaking compatibility. WFC's format is extensible for future features without destroying compatibility with previous versions. This is rarely seen in the TM industry.
Compatibility: WFC can read and write (import from, export to) the TMX format with minimal losses.
TM engine performance: The WFC TM engine is built to spot exact and/or fuzzy matches in less than half a second in most cases.
Integration: The WFC TM engine is totally integrated in Ms-Word: you don't need to run another application.
Networking: An unlimited number of users can share the same TM over a LAN (Local Area Network) or over the web using Wordfast Server.
WFC can use up to three simultaneous glossaries.
Size: the size of a glossary in WFC has been voluntarily limited to 250,000 entries. Most project-specific glossaries supplied by clients have far less than 10,000 entries - closer to 1000 for most. Important note: glossaries are meant to assist a translator with uncommon terminology, like technical jargon. Filling up glossaries with common words is a bad idea, it has consistently proved to decrease the tool's efficiency.
Format: like the TM format, the glossary format is plain text (Unicode or not), tab-delimited. It is therefore easy to feed terminology into a WFC glossary by simply copy-pasting it from a client's glossary, combine glossaries, etc.
Features: WFC glossaries offer a full range of services, from querying a term or expression, to full-fledged terminology recognition that highlights known terms in the source segment in real-time.
Fuzzy terminology recognition: WFC can recognize exact or fuzzy terminology in glossaries. Glossaries can be used as they are, or fine-tuned with the use of wildcards to meet special requirements.
Integration: WFC glossaries are totally integrated in Ms-Word - you don't need to run another application.
Networking: An unlimited number of users can share the same glossaries over a LAN (Local Area Network) or orver the web using Wordfast Server.
WFC can be used to translate any of the languages supported by Ms-Word. Scripts, rather than languages, are actually what WFC and Ms-Word handle - supported scripts include European, Latin-based scripts, Chinese/Japanese/Korean, right-to-left scripts (Arabic, Hebrew, etc.), Cyrillic, in addition to Central European, Greek, various forms of Hindi, etc.
WFC uses Ms-Word as translation editor, thereby taking all formats recognised by Ms-Word. WFC can handle files that have been tagged. WFC is compatible with the "tagged" format produced by RWS Rainbow, Trados Stagger etc., so WFC can easily be integrated in a Trados-based architecture to translate tagged files for FrameMaker, SGML, Quark Xpress, PageMaker, InDesign, etc. Note that the translation of tagged files requires great skills, and attention to minute details.
Wordfast Classic runs atop a locally installed version of Microsoft Word, from Microsoft Word version 2000 until the present version.
That includes Microsoft Word for Windows and for Mac. For the Mac, Microsoft Word 2016 and later are required.
Those versions of Microsoft Office should not be "online version", nor "cloud versions". They must be locally installed, capable or running without the internet.
Those versions must also support VBA (Visual Basic for Applications).
Note that the cheapest version of Microsoft Office ("personal" as opposed to "business" versions) may not support VBA.
How can I tell whether my version of Microsoft Word is locally installed, or a cloud version, and whether it supports VBA?
Linux users must install Microsoft Word on their machine (we don't provide support for that). If that is done, Wordfast Classic should run just as it runs on Windows.
(*) Your OS may use the F11 key for other purposes; you would need to press Alt, Fn, F11 together.
Please use our collection of Youtube videos for self-help, and select "Wordfast Classic" content. Videos can be paused, rewound, and offer the best opportunity to learn basic features.
This manual and its appendixes also provide detailed information on features.
See our list of peer-supported discussion groups
If nothing helps, and you have a valid license, sign in at www.wordfast.com, then click the "Hotline" icon to the right of the screen.
To prepare installation:
Know your Operating System: Windows, or Mac OSX.
Know your version of Ms-Word. It's under "About Word". Also note the vintage year, like 2010, 2013, 2019, etc.
Note: Cloud versions of Word cannot run Wordfast Classic: WFC runs on a locally installed version.
Unzip (extract!) the zipped file you downloaded from www.wordfast.net into a folder of your choice, or the desktop.
Unzipped versions of wordfast.dot and WFC9.en.UI are necessary for installation. Do not double-click wordfast.dot from inside the zip archive or folder!
Microsoft Windows users: Click here to learn how to unblock wordfast.dot if needed.
This is necessary for downloaded files, and only you can perform this step.
Click here to prepare Ms-Word for installation.
After extracting wordfast.dot and WFC9.en.ui out of the zip folder or archive, into one folder of your choice (or the desktop), open the extracted wordfast.dot with Ms-Word. Enable macros and/or "content" if prompted.
Press Ctrl+Alt+W or Alt+Enter. If installation is completed, press Ctrl+Alt+W or Alt+Enter again, a toolbar should appear:
After a successfull installation, you will not need to open wordfast.dot again.
If Ms-Word refuses automatic installation, you may need to temporarily change security level, and/or enable macros to allow installation.
|
If automatic installation cannot be completed, perform a manual installation.
Click the ▶ arrow for your Operating System:
Windows
If not done yet:
Click here to learn how to unblock wordfast.dot if needed.
Click here to set Ms-Word's security level if needed.
wordfast.dot should not be opened in Ms-Word as a document. Manual installation simply requires dropping wordfast.dot and WFC9.en.ui into the correct folder. Here is how to find that folder:
Windows 9x: \Windows\Application Data\Microsoft\Word\StartupMac OSX
Note to rare users of older OSX versions (pre-Catalina) running an older Word 2011, see Appendix 6
wordfast.dot should not be opened in Ms-Word as a document. Manual installation simply requires dropping wordfast.dot and WFC9.en.ui in the correct folder. Here is how to find that folder:
Apple imposes a strict Sandboxing policy on Microsoft Office, only allowing one predefined folder for macros, automation, or Ms-Word add-ons.
Here is how to find it:
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Press Ctrl+Alt+W or Alt+Enter. A toolbar should appear:
Manual installation is complete.
Close Ms-Word. Removing Wordfast is simply done by deleting wordfast.dot, as well as associated files (wordfast.ini, wordfast.cfg, etc.)
WFC does not modify your system in any way, does not add/remove entries to your registry base, does not add/remove fonts, does not create hidden files for protection or for hidden purposes, does not add/delete folders, does not add/remove DLLs etc. Thus, all it takes to un-install WFC is to delete wordfast.dot.
Important note
Operating systems have hidden or system folders, and Ms-Word's Startup folder may be located in a hidden folder (perhaps like C:\Documents and Settings\...).
If this is the case, set your Windows Explorer or your File search utility to browse and display hidden or system folders. To do so in Windows Explorer or in Windows' File search utility, use the Tools/Folder Options menu, then View then Hidden files and folders and make hidden files and folders visible. Other systems may have different methods for making hidden files and folders visible to the file explorer.
Log in to www.wordfast.net (use the password recovery procedure if needed). Once logged in, proceed to the Classic Download Page. Download the most recent version of WFC. Proceed as if it were a first installation.
You may wish to actually rename your previous Wordfast.dot (to Wordfast.old, for example) so that you may fall back on it if you need.
Your license, rights, licensing period, existing setup, etc. are not affected by upgrades.
Regularly visit www.wordfast.net or www.wordfast.com to make sure you are using the latest version. It is advised to upgrade between translation projects or jobs, (not during a translation project) when you are not under pressure. After upgrading, review your setup in case any setting slipped.
You must have downloaded and installed WFC before buying a license. You must have tried WFC on your system before you decide buying it.
An unlicensed copy of WFC is randomly limited to approximately 5,000 Translation Units. Note that without a valid license, WFC accepts larger translation memories, but it will only index the last 5,000 TUs.
If you intend to use WFC for professional activity, do not wait until the last minute to buy a license, as this process make take an hour to complete with a credit card, or longer with other means.
"Overdrawn" does not mean "expired", it simply means there were many installations.
You can install and reinstall WFC as much as needed for your personal use. However, to keep prices low and prevent abuses, we ask that you contact us after 4 (four) re-installations of WFC in the same year. Log in at www.wordfast.com then use the hotline to contact us, simply explaining why you need to install WFC more than four times in the same year (for example: Operating System crash, hard disk crash, moving to a new computer, etc.) Your request will most likely be granted, your yearly licensing/installation allowance will be reset, and you will be able to run WFC in full mode. Our policy ensures that your copy of Wordfast is not stolen, or distributed to others.
We will do everything we can to make sure you can use WFC without interruption for at least three years from date of purchase, or renewal.
Wordfast Classic licenses are valid for three years from date of purchase. Then they show as "Expired", in need of a license renewal.
To renew an expired license, log in at www.wordfast.net or www.wordfast.com with the credentials you received when buying.
See the complete Wordfast End User License Agreement (EULA) which you accepted when buying.
You will find FAQs on this topic here.
The entire WFC application is contained in one single template, wordfast.dot, and this file is the same for all platforms (PC/Windows, Mac, Linux, etc.). You can check www.wordfast.net from time to time or join a mailing list to see if an upgrade has been released.
The author or distributor(s) of WFC do not accept liability for the use or misuse of WFC. When buying a license, users recognise they had sufficient time to try and test WFC on their particular system and are willing to use it as it is, however imperfect WFC may be. Specifications outlined in this manual may be changed at any time without prior warning, and are not binding.
Press Ctrl+Alt+W or Alt+Enter to display the toolbar then click the
icon to open the main Wordfast dialog box:
Wordfast Classic wordfast.ini en-US>fr-FR F1:Help
This TM is active
Current TM:
C:\wordfast\NewTM-EN2FR.txt
Number of TUs: 234
File size: 28 Kbytes
Date: 2016-01-15 at 11:10:26
Source language: EN-US (English, Latin-1)
Target language: FR-FR (French, Latin-1)
Click the "New TM" button to create a new translation memory. You will be prompted for TMX-compliant codes of the source and target language used in your TM. You will be prompted to name and save the new TM. Close the WFC dialog box, you're ready.
A basic translation session consists of two steps.
Open the document to be translated, press Alt+Enter or click the Next Segment icon ⇩. The first source segment appears against a blue background. Type your translation in the target segment, which is the lower (green, yellow, or grey) box:
|
Press Alt+Enter, or click ⇩ to validate/close the current segment and open, then translate the next one. Translate the entire document that way. To pause or end translation, press Alt+End (or click ■ ), save the document, close Ms-Word if needed. To resume translation, click anywhere in the document and press Alt+Enter.
Proofreading: to edit a segment, place the cursor anywhere in that segment, press Alt+Enter to open it, edit it, then move to the next or previous segment (Alt+Enter, Alt+Down, or Alt+Up), or close the segment (Alt+End).
When proofreading is complete, click the Cleanup icon.
You're done! The translated document can be delivered. There is more to learn, but the essentials are covered.
Essential icons and shortcuts:
| Expand | ✚ |
(Alt+PgDn) expands a segment, when the sentence actually extends beyond a final punctuation mark.
A segment cannot be extended beyond a paragraph mark, page break, tabulator or table cell. Note: Double Alt+PgDn directly expands to the end of the current paragraph, in one time. | |||||||||||||
| Shrink | ▂ | (Alt+PgUp) reverses any use of the Expand segment command. | |||||||||||||
| Copy Source | ⤹ | (Alt+Ins or Alt+S; Ctrl+S on a Mac) copies the source segment over the target segment. | |||||||||||||
| Translate To Fuzzy | ⤸ | (Shift+Ctrl+PageDown) Translates until a non-exact match is found. | |||||||||||||
| Concordance | 🗘 | (Ctrl+Alt+C) scans the BTM & TM and displays all TUs containing a specific word. By default, the search for concordance is done in the TMs source segments. However, if, during a translation session, the selected expression is in the target segment, WFC will search for concordance in the TMs target segments. | |||||||||||||
| Reference | 🔍 | (Ctrl+Alt+N) scans the files located in the folder specified with Terminology/Reference search folders to retrieve and display reference material. | |||||||||||||
| Dictionary1 | 🕮 | (Ctrl+Alt+D) looks up a word/expression in the currently active external dictionary#1. | |||||||||||||
| Dictionary2 | (Ctrl+Alt+F) looks up a word/expression in the currently active external dictionary#2. | ||||||||||||||
| Glossary | 🗏 | (Ctrl+Alt+G) looks up a word/expression in glossaries. | |||||||||||||
| Memory | 🗐 | (Ctrl+Alt+M) displays the contents of the relevant TU above a proposed segment. | |||||||||||||
| Quality assurance | ✓ | (Shift+Ctrl+Q) toggles real-time QA on/off during translation. | |||||||||||||
| Quick-clean | (Ctrl+Alt+Q) cleans up a document without updating the memory (the real, full clean-up is performed from WFC's Tools tab). Quick-clean can be used if you revised the document by re-opening segments, so that changes are recorded in the TM. If WFC proposes to process bookmarks without cleaning up the document, see the note on Bookmarks | ||||||||||||||
| Data editor |
| Data Editor. This tool lets you browse, edit, maintain your TM, BTM, glossaries, and a few other resources used by WFC. | |||||||||||||
| Ctrl+Alt+X | Deletes the contents of the target segment. | ||||||||||||||
| Ctrl+Alt+Ins | Copies the source segment's text attributes/style to the target segment. This is useful if, on an opened segment, you have pasted text that has a different font or style. | ||||||||||||||
| Shift+Alt+Down | Forces WFC to either segment the text you selected (a selection of text is made), or re-segment from the cursor position (no selection of text is done). The selected text, or the cursor can be outside (usually after) the current segment, or inside the source segment. If the cursor is inside the target segment when you press Shift+Alt+Enter, WFC will close (and submit, or "save") the current segment as if you pressed Alt+Enter, skip the next segment, and open the second segment it finds. If Shift+Alt+Down is double-pressed, the behaviour is the same, except that WFC will skip the next paragraph rather than just the next segment. | ||||||||||||||
| Shift+Ctrl+G | Loads the glossaries into the toolbar, if their size is less than 200 Kbytes. That's practical only for pre-2007 Word versions. | ||||||||||||||
| Alt+Up | Can be used to return to the previous segment. | ||||||||||||||
| Alt+Right/Left | If more than one match was found in the TM, this shortcut will cycle through all TUs, inserting the target text. | ||||||||||||||
|
Ctrl+Alt+ Left/Right/Down |
🡄 🡇 🡆 | Selects the next/previous placeable or glossary term (in the source segment); Ctrl+Alt+Down ⇓ pastes the selected placeable at the position of the cursor (in the target segment). A placeable (an untranslatable element) is simply copied "as is"; with a glossary pair, the target term is pasted. | |||||||||||||
| F10 | Marks a segment as provisional. Read the note on provisional segments for this important feature | ||||||||||||||
| Ctrl+Comma | Toggles hidden text on/off. This lets you "preview" the final translation, then get back to full view. All editing, spell-checking, revision, etc. should be done in "full view", i.e. with hidden text visible. | ||||||||||||||
| Alt+F12 | Copies any selection of text (from any Ms-Word document) into the current target segment, if a session is opened. If, in the target segment, the selection has a zero length (it's just an insertion point), the selected text will be pasted at the insertion point. If the selection has any length, or if the selection (or insertion point) is outside the target segment, the text will be pasted at the end of the target segment. If the newly pasted text has a format or style that is different from the target segment's general style, remember that the Ctrl+Alt+Ins shortcut can copy the source segment's style and format to the target segment. |
Backup your original (source) document before translating it.
Alt+Home can be used to resume a translation session. It will re-open the segment that was last closed. If Alt+Home is used when the last document is not yet opened (as when you simply launch Ms-Word), it will re-open the last closed document, and resume translation at the last closed segment.
Beside Alt+End (validate + close the current segment, and end session), there are two other ways of closing the current segment and ending a session:
| Shift+Alt+End | Closes the current segment without writing (committing) it into the TM. | |
| Alt+Delete |
When a segment is opened (the source segment appears against a pale blue background), this shortcut deletes the contents of the target segment, then closes the segment (and the session) and restores the source segment as it was before segmentation. When no segment is opened, unsegments the entire document (returns the document to a source-text-only state). |
When you open a segment using Alt+Enter, the source segment is presented against a pale bue background . The target segment is presented against a gray background (no match: empty target segment) , or a yellow background (fuzzy match) , or a green background (exact match) .
If exact or fuzzy matches are found for the opened source segment, target text is suggested in a drop-down list called AutoSuggest below the target segment.
In an opened segment, the Ctrl+Alt+M shortcut (or the 🗐icon) shows/hides sthe details of Translation Unit (TU) for the selected suggestion, above the opened source segment.
Here is an example using a 85% fuzzy match:
| |||||||||||||||||||
| Page 1 on 25 7,8765 words English (US) |
Minimalist display
WFC can temporarily reduce the view to a minimalist layout when the current segment is inside a table cell, a bulleted list, a textbox, a footnote,
or any other section where displaying accessories can be problematic for technical reasons.
In this case, only the TU's source segment is displayed above the opened segment. Ms-Word's status bar shows the TU's metadata such as date, User ID, attributes, etc.
The highlighting of differences is still done.
In combination with AutoSuggest, the minimalist view carries as much information as the full view.
The minimalist view:
The Minimalist view can be set as permanent in Setup > View if you use a small monitor or screen, such as a laptop.
If that is the case, note the Ms-Word shortcut Ctrl+F1, which show/hides the huge ribbon. On a Mac, click the small "Reduce" icon on the ribbon's side.
Note: If AutoSuggest has more lines than what is displayed, pressing the Down/Up arrows can cycle through all those lines (there may be more lines than what is visible).
Here is the same segment using the minimalist view:
| |||||||||||||||
| TM (85%) - 2016-03-14 11:23:18 by YC ~client: EU-DEP ~ domain: IT |
If penalties are used, those appear in red color in a full segment. The example below assumes that Penalty for case difference was set to 2 under Translation Memory > Attributes and penalties, and penalties were checked as "Enabled":
| |||||||||||||
| Page 1 on 25 7,8765 words English (US) |
In translation tools, one class of terms is called placeables. This broad category is made of terms that do not change from source to target for various reasons. They are simply not translated. In the example below, the proper name and the date are considered placeables:
| Please welcome Zbigniew Brezinski, our 1974 award recipient. |
| Merci d'accueillir Z| |
|
The placeable concept is what fuels the AutoSuggest feature. In most cases, typing the first letter of a placeable triggers an AutoSuggest drop-down list of choices. WFC tries to place the best candidate at the top of the list.
If needed, select the proper choice with the Up/Down arrows, then press Enter: the selected placeable is now "placed" (whence its name) in the target segment.
| Please welcome Zbigniew Brezinski, our 1974 award recipient. |
| Merci d'accueillir Zbigniew Brezinski| |
In the example above, simply typing Z triggered AutoSuggest. Pressing Enter places the entire Zbigniew Brezinski in the target segment. There are two benefits to this method:
Note that Ctrl+Alt+LeftArrow and Ctrl+Alt+RightArrow also let you select a placeable, then place it with Ctrl+Alt+DownArrow. That method, inherited from earlier versions of WFC, is slower and less intuitive, but can be used in complex situations.
Here is a presentation of what WFC considers placeables:
The methods below can be used to prepare documents before translation, preventing text from being segmented. Note that, after cleanup, those "excluded" parts of the document will still be present - and obviously, left untranslated.
Create a new style named "tw4winExternal". That style must be character-based (not paragraph-based). For practical purposes, keep that style in your default template, aka the "Normal" template, for future use. Apply that style to untranslatable portions of the document. This is the recommended way. Assign any font attribute you want to that style, then apply that style to portions of text to be excluded. Applying the style can be done programmatically by using a macro, or manually, case by case. Note that a shortcut can be assigned to a style.Another method is to use a font attribute (either Font > DoubleStrikeThrough,
or Font > Hidden text). Font attributes are easier to handle.
Apply that font attribute to the untranslatable text, then check the corresponding option in Wordfast > Setup > Segments > "Use ... as untranslatable attribute" option.
DoubleStrikeThrough is the recommended font attribute for text exclusion, while Hidden Text is kept only because some translation clients got used to it.
If your client asks what option is the best, go for DoubleStrikeThrough. If other parts of the document already have that font attribute (rare), recommend the tw4winExternal style, or Hidden Text.
Note to long-time WFC users: the much-loved Marching Red Ants font animation was deprecated by Microsoft in Ms-Word 2007, and removed after 2016.
WFC introduced it in the early 2000's, then kept it for backward compatibility until 25 May, 2021.
RIP the scarlet hymenopteres and their 20 years of active duty.
Likewise, Highlight Gray 25% was also used for a few years, then abandoned by WFC for technical reasons.
Text highlight is fragile because, unlike DoubleStrikeThrough, it is dependent on an obscure setting (Files/Options/View/Show Highlights)
that could be unwillingly turned off by the translator, or by concurrent add-ons, causing frantic calls to the hotline.
When opening an already-segmented segment, where the contents of the target segment does not correspond 100% to the one in the TM, the target segment will be framed in red. This can occur if you translate a document, then manually edit typos in some target segments (without opening the segments with WFC for edition - manually here means you directly edit the text in Ms-Word). The red frame around the target segment indicates that the target text has been changed since the time the segment was originally written into the TM.
|
Pressing Ctrl+Alt+M and inspecting the target segment thus displayed against a gray background should bring up the difference. In the example below, the French "entouré" in the TM does not match "encadré" in the target segment.
|
Committing the red-frame segment (moving out of it with Alt+Enter or properly ending the session with Alt+End) will stamp the corrected version of the entire TU into the TM, and erase the existing TU which caused the red frame. When re-opening the segment, the red frame should be gone.
Maintaining segment integrity is crucial in WFC; restoring broken segments is difficult and time-confusing. It is the main drawback when using Ms-Word as a translation editor.
Ideally, when translating, typing should only be possible in the confines of the opened target segment.
However, WFC has opted to still allow translators full freedom to navigate/edit the source document as usual during translation. This is why some keys are monitored and protected to avoid hurting an opened segment.For example, hitting Backspace with the cursor at the beginning of the target segment, or Delete at the end of a segment, can be destructive.
Protected keys are: Escape, Enter, Delete, Backspace, Ctrl+X, Ctrl+V, Ctrl+A, Home, End, PageUp, PageDown, KeyUp, KeyDown, KeyRight, KeyLeft.
If you need to take a break, finalize and close the current segment (Alt+End). Do not leave a segment opened for too long, unless you are the only soul in the house, cats & ghosts included.
Navigation keys.
KeyUp, KeyLeft, KeyDown, KeyRight can send the cursor outside the target segment, but still inside the currently opened segment area,
into a WFC "service zone", like AutoSuggest, notifications, delimiters, which are very sensitive.
This is why those navigation keys are protected.
To "leave" the target segment using the keyboard: use PageUp (once to move from target to source, one more time to leave the entire segmented zone),
or PageDown.
Of course, the mouse can achieve the same navigation moves.
See the relevant Pandora's Box section to prevent WFC from monitoring any of those keys.
Note that disabling Enter, KeyUp, KeyDown, prevents AutoSuggest operation!
Disabling key protection requires expertise, and is not recommended unless you know what you are doing.
This disabling feature exists to allow debugging when difficult shortcut situations occur (other applications or add-ons monitoring the same keys).
Note that the Escape key temporarily inhibits all protections for the duration of the currently opened segment,
and displays the segment in an old-fashioned way, with all segment delimiters clearly visible.
This is useful to repair a broken segment.
If you want to leave a segment in a temporary, "provisional" state because it has not been completely translated (because its translation requires knowledge you will receive only later, or because you're missing some specific terminology), press F10 on the segment while it is opened. This will mark the current segment as provisional with a fluorescent yellow marker, and move to the next segment:
|
Later (the translation session being closed, i.e., no segment being opened), pressing F10 again will take you back to the first provisional segment in the current document and open it again so you can finalize it. When you close (validate, or commit) the segment by pressing Alt+Enter (Next segment) or Alt+End (End translation session), the segment will lose its provisional segment status, and the yellow marker will be removed.
A provisional segment can be finalized (its translation completed) at any time, even days after you marked it with F10.
!
Cleaning up a document is impossible if it contains provisional segments marked with ⎕ .
If you deliver uncleaned (segmented, or bilingual) documents, make sure they do not contain provisional segments. Simply press F10 on a document to see if it contains any provisional segment.
This method is safer and faster than leaving marks like $$$ or XXX, which can be forgotten.
This section lets you select a TM or create a new one, define TM attributes, set TM rules, set up a Background TM, set up a remote TM with Wordfast Server or Wordfast Anywhere, and set up machine translation.
Wordfast Classic wordfast.ini en-US>fr-FR F1:Help
This TM is active
Current TM:
C:\wordfast\NewTM-EN2FR.txt
Number of TUs: 234
File size: 28 Kbytes
Date: 2016-01-15 at 11:10:26
Source language: EN-US (English, Latin-1)
Target language: FR-FR (French, Latin-1)
When creating a new TM, WFC will prompt you for TMX-compliant language codes for the source and target languages. These codes consist of 5 characters (2 characters for the language, a dash, and 2 characters for the country or local variant).
Here are a few language codes. A larger list of TMX-compliant language codes can be found here.
| af-ZA (Afrikaans) | fa-01 (Farsi) | no-NY (Norwegian) |
| ar-01 (Arabic, Egypt) | fi-FI (Finnish) | pl-PL (Polish) |
| be-01 (Byelorussian) | fr-CA (French, Canada) | pt-BR (Portuguese, Brazil) |
| bg-BG (Bulgarian) | fr-FR (French, France) | pt-PT (Portuguese, Portugal) |
| ca-ES (Catalan) | hr-01 (Croatian) | ro-RO (Romanian) |
| cs-CZ (Czech) | hu-HU (Hungarian) | ru-RU (Russian) |
| da-DA (Danish) | in-01 (Indonesian) | sh-01 (Serbo-Croatian) |
| de-AT (German, Austria) | is-01 (Icelandic) | sk-01 (Slovak) |
| de-CH (German, Switzerland) | it-CH (Italian, Switzerland) | sl-01 (Slovenian) |
| de-DE (German, Germany) | it-IT (Italian, Italy) | so-01 (Sorbian) |
| el-GR (Greek) | iw-IL (Hebrew) | sq-01 (Albanian) |
| en-CA (English, Canada) | ja-JP (Japanese) | sv-SE (Swedish) |
| en-GB (English, UK) | ko-KR (Korean) | tr-01 (Turkish) |
| en-US (English, USA) | lt-LT (Lithuanian) | uk-UA (Ukrainian) |
| es-AR (Spanish, Argentina) | lv-LV (Latvian) | vi-VN (Vietnamese) |
| es-CL (Spanish, Chile) | mk-01 (Macedonian) | zh-CN (Chinese, PRC) |
| es-ES (Spanish, Spain) | mt-01 (Maltese) | zh-SG (Chinese, Sing. simpl.) |
| et-01 (Estonian) | nl-BE (Dutch, Belgium) | zh-TW (Chinese, Taiwan, simpl.) |
| eu-01 (Basque) | nl-NL (Dutch, Netherlands) |
Beside its own native format, WFC can open TMX translation memories. TMX is the standard format for Translation Memory eXchange. If your client supplies you with TM data, ask for a TMX export.
For example, to re-use a WFC TM with Trados Translator's Workench (TWB):
Reorganize. The Reorganize button reorganizes ("indexes") a TM. Since this will usually reduce the size of the TM by permanently erasing TUs that were marked for deletion, it is advised to perform this reorganization before e-mailing or archiving a TM, or before sharing it with another translator. Reorganising a TM should also be done if the TM seems to return no matches.
Note: When exporting or importing a WFC-generated TMX TM to or from another tool, the usual reason for failure is consistency in TMX language codes across the two tools.
Working in network mode (sharing a WFC TM over a LAN)The same translation memory can be shared by an unlimited number of users over a LAN (Local Area Network). Every WFC user that shares a TM over a LAN should simply open the shared translation memory through the network.
Windows users: use mapped networked drives/folders rather than long network drive/folder names. To map a network drive, use Windows Explorer's Tools/Map Network Drive menu and assign a volume letter to the drive (or even to the drive + folder) where the shared TM is located. As a result, the TM's path would be, for example, Q:\MyFolder\MyTM.Txt rather than \\BillysMachine\MyFolder\MyTM.Txt.
Every user should have a different set of user initials.
Glossaries can be shared over a LAN. Proceed as with TMs.
Do not index a glossary when it is shared (WFC will prevent you from doing so anyway).
As with TMs (see above), use mapped networked drives.
Wordfast Classic wordfast.ini en-US>fr-FR F1:Help
This BTM is active
Current TM:
C:\wordfast\BackTM-EN2FR.txt
Number of TUs: 8234
File size: 208 Kbytes
Date: 2015-01-15 at 10:22:16
Source language: EN-US (English, Latin-1)
Target language: FR-FR (French, Latin-1)
Select BTM: A background translation memory (BTM) is a read-only translation memory which WFC will scan for exact or fuzzy matches after scanning the current TM. If a match is found in the BTM, Ms-Word's status bar and a beep sound will inform the translator that the proposition comes from the BTM. In the AutoSuggest drop-down list, BTM propositions have a match score in green, rather than in blue.
Make sure the "This BTM is active" checkbox is checked for the BTM to be used.
Which TM comes first?
By default, if the BTM is used, the BTM is preferred over the TM. If the BTM and the TM (and WFS or WFA, when applicable) yield Translation Units (TUs or "matches") with the same match rate, the BTM's TU will be displayed first. The Alt+right/left shortcuts can be used to display other TUs.
Note that there is a setting in the AutoSuggest (AS) setup that decides which proposition (from the TM, BTM, WFA, WFS, MT1, MT2, etc.) is pasted in the empty target segments when the segment opens.
Wordfast Classic wordfast.ini en-US>fr-FR F1:Help
Use a remote TM & glossary VLTM WFS admin password (optional) Note: remote terminology appears as Glossary #3 Enable on already-translated segments Use only for concordance
This section of Wordfast offers a connection to TMs from a Wordfast TM Server.
In Wordfast Anywhere, get the URL from "TMs & Glossaries > Setup > View/Edit". It looks like this:
wf://CznlO71SE7.EN2FR:@207.223.244.237:47110/14+?$yCv1SThat way, you can connect to the TM and glossary that are currently active in your WFA account. WFA TM connection is read-write. You can even set your TM as "shared" in your WFA account, if you wish so, and invite others to share it.
Wordfast Server
This option is reserved for organizations that have set up a Wordfast TM server.
A free version of Wordfast Server in demo mode for up to three simultaneous connections can be downloaded from http://www.wordfast.net/zip/WfServer.zip.
It can be used locally by translators who run very large TMs (over one million TUs), or who want to share their TM with one or two other translators.
Which TM comes first?
If a remote TM and the TM (and the BTM as well, when applicable) yield Translation Units (TUs or "matches") with the same match rate, the TM's TU will be displayed. The Alt+right/left shortcuts can be used to display other TUs.
The AS (AutoSuggest) section in the setup can be used to set the order of preference, for example, having the VLTM, or the BTM, come before the TM.
Wordfast Classic wordfast.ini en-US>fr-FR F1:Help
User ID JD John Doe (5)▼ Client MS MedicSoft Inc.▼ Subject (5) CH Chemistry▼ Enable attrib. ▼ penalties ▼
Penalty on WFA/WFS
Penalty for case difference=
Penalty for different numbers=0
Penalty for whitespace difference=0
Penalty for different quotes/apos./dashes=0Enable general
penalties
The TM Attributes tab displays five attributes, four of which can be customised, the first attribute being reserved for the User ID (User initials and name). I recommend reserving attribute #2 for Subject, and attribute #3 for Client, as in the example provided in WFC, to facilitate the interchange of TMs. You remain free, however, to define attributes according to your own needs. Use the Sample button to load a set of typical attributes, which you can then customise.
You can freely edit attribute names on the left textbox.
Then click in the corresponding drop-down list to add attribute items (also called attribute values)
Entries consist of a mnemonic (an abbreviation, made of 2, 3 or 4 letters) followed by a space, then the narrative. WFC will record only the mnemonic in the individual TUs, to optimize space.
! Note: The first attribute is always the "User ID" attribute. By default (if you don't specify a User ID or name), the value for this attribute is the current Ms-Word user initials and name, as they are found in Ms-Word/Tools/Options or File/Options/User info. You can, however, customize this User ID as you wish. If the TM was used by other users, the drop-down list will show all the translators who have used the TM in the past (maximum number of translators: 60). If you workgroup, this feature lets you see the TM's pedigree.Attributes are stored in the current WFC setup - the INI file.
! Note: penalties are brought to the translator's attention using a red color. The match rate will appear bold and red to warn the translator that a temporary penalty has been applied. Note that if a "100% match" turns fuzzy because of a penalty, and the proposed match is accepted as is, the translation unit (TU) is not written into the TM. With a 100% match, a new TU will be entered into the TM only if the target segment was edited. This is avoid the pullulation of nearly-similar TUs that quickly bloat a TM.There are two types of penalties: absolute penalties and relative penalties.
Those are defined for attribute values (i.e., items in the drop-down list). When WFC proposes a TU which has that attribute value, it will receive the corresponding penalty.
Example: your translator ID is JTB John T. Bisham. You import, in your TM, 200 TUs coming from another translator whose ID is MAT Mark A. Tweed.
You wish to unconditionally apply a penalty of 5 to propositions coming from TUs created by Mark Tweed.
Create or edit the
MAT Mark A. Tweed
attribute entry so it reads
MAT Mark A. Tweed (5)
From then on, every time a proposition comes from a TU created by Mark Tweed, it will have a penalty of 5. As a result, a Mark A. Tweed TU will never appear green, it will appear as 95% match at best.
Those are defined per attribute (in the attribute name caption). These penalties will be applied if the particular TUs attribute value is different from the attribute value of the current session (as you defined it in WFC's TM Attributes section).
Example: you apply a relative penalty of 8 to the User ID attribute. Edit the User ID caption so it reads User ID (8). From then on, if a TU's User ID is different from the one currently defined - supposedly your ID - then the TU will receive a penalty of 8, regardless of which translator it is.
Absolute and relative penalties are cumulative. So, if Mark A. Tweed already has an absolute penalty of 5, and the entire User ID category has a relative penalty of 8, then a TU with Mark A. Tweed will receive a total penalty of 13.
The basic purpose of penalties is that a TU, which would otherwise appear green (an exact match), does not appear green but yellow, so that the translator's attention is drawn at that point. Penalties should be modest (a penalty of 2 is more than enough enough to prevent a TU from appearing green), because, if they are cumulated, they may actually bring the match rate below the fuzzy threshold. Penalties for TUs created by machine translation, however, are traditionally strong (10 to 15).
One other purpose of the Attribute system, using the TM/glossary editor utility is to manage (extract, merge, classify etc.) TMs by taking into account their TUs' individual attributes.
Penalties on the origin of TUs
In the TM engine, the matching algorithm's task is to find the best suitable match for the source segment you are currently translating. In some cases, WFC uses a substitution algorithm to update the proposed segment and bring it closer to an exact match, requiring less work from the translator. The elements that are updated or substituted are typically untranslatable items (like numbers, brackets and punctuation, fields, tags), also called placeables. The goal is to relieve the translator from the chore of spotting and updating placeables.
Needless to say, that algoritm, a blind automat working in all languages, is not perfect. It was created, however, to be of good help, making correct substitutions most of the time.
The substitution method is obvious when numbers are involved. WFC considers the following two sentences to be "exact" matches:
The net weight is 1,000 Kg.
The net weight is 2,000 Kg.
This is so because WFC can easily detect numbers and carry out a substitution. In this situation, numbers like 1,000 or 2,000 are considered placeables by the TM engine, and they are updated to reflect the document's reality rather than the TM.
The method is a great help and time-saver in most situations. "Most" here is so overwhelming that, by default, most translation tools are set to automatically substitute placeables like numbers, or fields.
This method can fail when the placeable substitution requires a grammatical or syntactical update of the target segment - a task which WFC cannot perform. In the following example:
The process takes 2 years to complete.
The process takes 8 years to complete.
The substitution process (replacing 2 with 8) would work pretty well with most languages, but would produce a grammatically incorrect sentence in a few languages, like Russian, where plural forms above 4 are usually differently
Some penalties only apply to exact (so-called 100%) matches, others on lower values of match values, exact or fuzzy.
Penalty for case difference: (100% only) this penalty is applied when an exact match is found in the TM, but case is the only difference. Example:
Meet us at the ATA!
MEET US AT THE ATA!
Penalty for different numbers: (100% only) This penalty is applied when different numbers are found in a segment. Example:
The process takes 2 years to complete.
The process takes 8 years to complete.
Penalty for whitespace difference: (100% only) This penalty is applied when an exact match is found in the TM, but the only difference is in spaces found at either beginning or end of the segment, or where there is a different number of repeated spaces within the segment. Example:
Meet us at the ATA!
Meet us at the ATA!
Penalty for different Quotes/Apostrophes/Dashes (QADs): (100% only) this penalty is applied when an exact match is found in the TM, but the types of QADs are different.
Note that ' is sometimes used as a closing quote, sometimes as an apostrophe. WFC assumes ' is a closing quote when ' appears before it.
WFC is blind to QADs when a 100% match is found, and when, in the TM's segment, the only difference is made of different QADs which WFC can substitute without any ambiguity, as in:
This is a "quoted sentence".
This is a " quoted sentence ".
This penalty will force WFC's TM engine to consider the two segments above as not being 100% matches.
Wordfast Classic wordfast.ini en-US>fr-FR F1:Help
When editing (changing) a 100% match=0 (Overwrite TU)
When re-using an existing TU, update it if attributes are different=0 (No)
Fuzzy threshold
The fuzzy threshold is the minimum match rate, in percentage, (resemblance between two source segments, where 100% means "identical") under which the TM engine will not propose Translation Units from the Translation Memory.In-Context Matches. This features enables In-Context Matches (ICM). ICMs are matches where a sequence of three segments (previous, current, and next, in the document and in the TM) all match at 100%. The idea is that if a segment is embedded in a series of three exact matches, the trustworthiness of that segment greatly increases. ICMs have a score of 101 so they are picked first in case there are other competing 100% matches. Remember that match scoring, in TMs, carries little linguistic sense.
Enable a level of ICM support in WFC's TM rules tab.
If your TM had no previous ICM detection, you can reprocess it to enable ICM matches:
Editing an existing 100% TU
A TU is re-used if you validate a proposed 100% (green) TU without editing (modifying) the target segment (the translation). A TU is edited if you edit (modify) the target segment. The following rules apply immediately after you validate such "100% match" TUs, to control the way they are stored into the TM.
This setting offers 4 choices:
In case there are many identical translation units in the TM, the first match proposed by WFC should be the most recent one, based on its date stamp.
When re-using an existing TU, update if attributes are different
If the currently active attributes (as set in WFC > Translation Memory > Attributes) are different from the candidate TU's own attributes (as found in the TM), you may choose to update the TU in the TM with the new set of attributes (the TU will be rewritten "as is", but the current set of attributes will replace the existing ones). Check the "Update existing TU if attributes are different" checkbox. The usage counter will be incremented, and the new set of attributes will replace the TU's existing attributes; source and target text remain the same.
Wordfast Classic wordfast.ini en-US>fr-FR F1:Help
Enable remote MT Enable local MT
Context MT: MT document in advance for better context. Monitor CMT
Enable on already-translated segments
During a translation session, WFC can request an on-the-fly translation from a remote, or locally installed Machine Translation engine.
Using the top checkboxes, please enable remote (web-based) Machine Translation, and/or local MT.
Context MT (CMT)
Traditional MT in translation tools, as of Spring 2023, is performed one segment at a time.
However, most MT engines are now equipped with context detection, leading to better disambiguation when terms have multiple meanings.
Wordfast Classic can now submit the entire document for machine-pretranslation.
This is done when a translation session starts on a new document (Alt+Down).
After a minute, sometimes less, a temporary file is created in WFC's ancillary file folder, containing a temporary TM created by aligning the source document and its MT-generated "translation".
That temporary TM will only be used when translating that given document. As with the older MT model, if you edit/validate a CMT proposition, it will be written into the currently active MT, if applicable.
Note that all the above (temporary MT creation and usage) is automatic and transparent, the translator does not need to intervene.
Here are a few benefits:
Monitor CMT This is for engineers, and curious minds!
If you select "Context MT", this sub-option forces WFC to re-query individual segments again, when you open them.
Note that if you pay for MT, this doubles the cost.
The idea is to monitor whether MT one segment-at-a-time, versus MT on-an-entire-document, makes any difference:
| ||||||||
The above is a real-life example done in May 2023. It supposes that Monitor CMT is checked.
Furthermore, the Context MT translation is more elegant, although that is secondary; and the correct gender is applied to utilisé because Emerald (as a programming language) is masculine, whereas émeraude (the precious sone) is feminine in French.
When Monitor CMT is checked, WFC compares the two propositions, and colors differences with a red font.
Note that the score for CMT ranges from 98 (most likely unit) down to 80%, not 75%.
The reason is rather complex. The problem with aligning a pretranslated document is that entire paragraphs are first MTed; and only then are they segmented.
Since segmentation, in some circumstances, can be ambiguous (no tool can segment 100% correctly all the time), Wordfast Classic generates various combinations of TUs to cover possible cases.
Only at translation time, when the translator opens a segment (and may expand, or shrink it, to make up for a faulty segmentation)
will Wordfast Classic pull TUs from the temporary TM, and compare them to the source segment, finding the closest match.
Multiple matches may be proposed, in order of likelihood, and this is why an dedicated scoring method was devised.
Enable MT on already-translated segment. This specified whether the MT engine is queried even if the text is already segmented. Some MT engines work at a cost, so leave this checkbox unchecked to avoid being billed for segments that you already translated.
Reset. This button resets all MT engines to their default settings in case "Custom MT" changes have gone out of hand.
Wordfast Classic wordfast.ini en-US>fr-FR F1:Help
MT provider API or subscription key/ID Google▼ 1f5d969380d17897b60f4c841a64ca48 Microsoft▼ d961f59380d178997b60f4c841a WorldLingo▼ No MT▼
WFC can connect to various Machine Translation sources. Note that many of those sources are subscription-based, and you will need an API key (or subscription ID) to connect to them.
WFC has a special deal with WorldLingo, which is why WorldLingo MT is free and unlimited for WFC users (no API key required). WL covers a wide array of languages. If your language pair is covered, as the saying goes - go for it!
Multiple MT sources can be enabled at the same time. It's an exciting way to have giants like Microsoft, Google, DeepL, ModernMT et al. compete to offer you their best MT. Oh well, your skills are still an order of magnitude ahead of the multi-billion-dollar giants. But hurry - the beasts are closing in.
! Note on confidentiality, secrecy, NDA compliance, etc. As is obvious, using a remote MT resource means that you content, as you translate it, travels over the web to a service that will machine-translate it, then send back the proposed translation. There are two importants things to note:
Wordfast Classic wordfast.ini en-US>fr-FR F1:Help
MT name JSON keyunlock Custom ▼ URL Headers Session Post
If your remote Machine Translation provider is not listed as built-in engine, it is possible to create a custom connector for it. This is only possible if your MT provider's API is using a REST standard, and returns results in a JSON, or similar, format like XML, HTML, or pure text. That is the case with major MT providers currently available with WFC (Google, Microsoft, WorldLingo, DeepL, MyMemory, ModernMT).
Note: this section is DIY (Do It Yourself). It takes a good knowledge of the HTTP, REST, JSON standards. Our hotline cannot assist in the customization of an MT engine, because that requires knowledge of the remote provider's specifications. However, public discussion groups may offer help.
The built-in engines are listed, and can be displayed in read-only mode so that you can see how WF Classic runs using their specifications. Since all MT providers publish their API specifications, this will help you understand what needs to be done to create a custom MT connector.
In exceptional cases where you need to edit the specifications for a built-in MT engine, click 'Unlock' to make those parameters editable.
To create a custom connector, select the "Custom" element in the drop-down list.
Note the various elements:
Inside the above fields, a few elements are included between accolades: those are placeholders that WFC will replace with real data.
{ss} will be replaced with the source segment to be translated. This parameter must be present.
{sl} and {tl} are optional. They will be replaced with your source and target language codes (two-character, lower-case). But you can hard-code them if you prefer (write the real values). {sl} or {tl} can be entered as upper-case like {SL} or 5-character codes like {sl-sl}. WFC will adapt to the model. If you only work in one language pair, it is advised to hard-code your language codes where they belong (URL, and/or header, and/or POSTed data). Only your MT provider can tell you what those codes are. Most well-behaved MT providers use lower-case, two-character ISO language codes, as in a standard Wordfast TM, like en for English, fr for French, etc.
Amazon Translate
Amazon provides neural Machine Translation.
You will need to open an account with Amazon's AWS Translate service.
That account will provide you with an Access key and a Secret key. Both keys are necessary.
The cost of MT is comparable to other mainstream MT providers.
This setting is done in the "Customize MT" tab, as follows:
| MT Name | JSON key | |||
| AM:Amazon | TranslatedText | |||
| URL | ||||
| https://translate.eu-west-3.amazonaws.com | ||||
| Session headers | ||||
| Request headers | ||||
| {"SourceLanguageCode":"{sl}","TargetLanguageCode":"{tl}","Text":"{ss}"} | ||||
| Post | ||||
"Session headers" and "Post" remain blank. Once the above setup is done,
have your Amazon Access key and Secret key ready in another application, so you can copy-paste them.
Click "Remote TM", select "Amazon" in the drop-down list of available MT providers.
In the long textbox to the right, copy-paste (better not retype!) your Access key, then add a space, then copy-paste your Secret key.
As a result, both keys are now pasted, separated with a space.
Click back into "Customize MT", select "Amazon" in the list of available MT engines, click "Test".
Note: Amazon services are done by region. The above example uses a region in Western Europe. The region is written inside the URL. In the above example, it's eu-west-3. Although any region can be used, you may want to enter your region there, as provided by your AWS account. Simply update the region in the URL.
Intento Custom MT Settings
Intento is a commercial MT provider where you can obtain various Machine Translation sources like Google Translate, Microsoft Translate, Amazon Translate, and many others, while maintaining only one subscription for the multiple sources.
You must open an account with Intento (www.inten.to) then obtain an API key from them before proceeding.
Setup details
This setting is done in the "Customize MT" tab, as follows:
| MT Name | JSON key | |||
| IN:Intento | results | |||
| URL | ||||
| https://api.inten.to/ai/text/translate | ||||
| Session headers | ||||
| Request headers | ||||
| apikey: {apiKey} | ||||
| Post | ||||
| {"context":{"text":"{ss}","from":"{sl}","to":"{tl}"},"service":{"provider":"ai.text.translate.microsoft.translator_text_api.3-0"}} | ||||
"Session headers" remains blank. Once the above setup is done, click "Remote TM", select "INTENTO" in a drop-down list of available MT providers, then copy-paste (better not retype!) your API key. Click back into "Customize MT", select "INTENTO" in the list of available MT engines, click "Test".
You must hard-code the one MT provider you need in the "Post" section of the custom setup.
In the above example, it's ai.text.translate.microsoft.translator_text_api.3-0 .
Yours can be different.
WFC only supports one MT provider in an Intento connection.
Tip If you want multiple MT sources from INTENTO, you can add more INTENTO custom engines, each with a different MT source entered in the "Post" parameter. If that is the case, give a different MT Name to every Intento custome engine, for example IM:IN-MS (if Microsoft is used), IA:IN-AMAZON (if Amazon is used), etc.
Wordfast Classic wordfast.ini en-US>fr-FR F1:Help
Ms-Word-based machine translation (see manual)
Local MT engines can be Ms-Word add-ons, such as Systran™, Power Translator Pro™, PROMT Reverso™, etc. After purchase and installation, these MT programs act as Ms-Word add-ons, just like WFC. There are four typical ways your Ms-Word MT add-on operates to have the document, or a selection of text, or the current paragraph, machine-translated:
For each method, you will need to provide two parameters that tell WFC how to request the translation. These two parameters are entered with a comma as separator. Here are the parameters you will have to provide for each situation:
The menu name, then the sub-menu that triggers the translation of the selection or the current paragraph (not the entire document's translation). This could be "Systran,Selection" or "Translate,Selection" for example, with Systran 4, or Power Translator Pro.
The toolbar name and the icon name. Your MT add-on's toolbar name is found in Ms-Word's "View/Toolbars" menu. You don't need to quote the entire toolbar's name, just a keyword that is special to this toolbar's name (maybe like "PROMT" or "Systran"). The icon name appears as "tip" when the mouse hovers over the icon. Note this icon name. This could be "Translate paragraph" for example. So the entire parameter could be "PROMT,Translate paragraph".
Select a portion of text and right-click on it. Note the name of the contextual menu that's used to translate the current paragraph (this could be "Translate paragraph", for example). The parameter to enter would then be "Contextual,Translate paragraph".
Note the macro's exact name (like "MTMacro"). The parameter to enter would be "Macro,MTMacro".
To set up MT activation:
Go to WFC's Translation memory/MT tab. Check the "Menu, sub-menu for MT" checkbox.
In the text box immediately after the checkbox, enter the parameter as defined above.
If you work on tagged files with an MT package that does not support tags, check the "Remove tags" option (if you are not sure what this means, check "Remove tags").
Close WFC. In Ms-Word, test your translation package on a short sentence to see if it is correctly set up and running.
This is the normal procedure, and it works with Systran, Power Translator Pro, PROMT Reverso on all versions, and most other packages. Some trial-and-error may be required to have it run.
On systems running Systran4, the Systran add-on that links Ms-Word to the Systran engine must be in Ms-Word's "Startup" folder (as is the case after Systran's regular installation procedure is carried out), so that it is loaded on startup. Systran may not work if its add-on is simply activated after startup.
Wordfast Classic wordfast.ini en-US>fr-FR F1:Help
This glossary is active
Current glossary:
C:\wordfast\myGLO-EN2FR.txt
Number of entries: 834
File size: 22 Kbytes
Date: 2017-09-15 at 08:09:26
Use fuzzy terminology recognition
Lock target case on entire glossary
The colors used to highlight terminology are set to turquoise for glossary #1, green for glossary #2, gray for glossary #3.
The colors can be customized using the Pandora's Box command GlossaryXColor.
Getting started
In Ms-Word, create a new document. In this new document, type a short series of source terms followed by a tabulator (press the tabulator key, shown here below as ↦ ), followed by their translation, then Enter, as in the following example:
work visa ↦ visa de travail country ↦ pays country of birth ↦ pays de naissance
Name and Save the new document as "Text-only" (preferably Unicode or Encoded Text). Congratulations, you have created a WFC glossary. Close the glossary document.
In WFC, go to the dialog box shown above (Terminology/Glossary X). Click the "Select glossary" button, find and open the glossary you just created (in the "File type" list, select "Text", or "All files").
Click the "Reorganise" button. This will make WFC sort the glossary on source terms, and index all entries.
Make sure the "This glossary is active" checkbox is checked, so WFC performs terminology recognition using this glossary during translation sessions. If you uncheck this checkbox, terminology recognition is suspended.
Close WFC.
In a new document with some text that includes any of the source terms listed above (like "work", "country" etc.), start a translation session. Normally, these terms should be highlighted in light blue when a source segment includes them. This means that WFC has recognised that these terms are present in the glossary #1. You can select blue-highlighted terms with the Ctrl+Alt+Left/Right shortcuts and see their translation in the status bar, or copy their translation at insertion point in the target segment with Ctrl+Alt+down. If you place the cursor on a blue-highlighted term and press Ctrl+Alt+G, the glossary drop-down list will open and show the glossary entry. This same toolbar also enables you to open the glossary editor window.
The "Lock target case" checkbox forces a glossary-wide case lock on target terms. See further below for an explanation of "Lock target case", a feature which also exists at the level of each individual glossary entry, which is the recommended option.
Adding terminology
Wordfast Classic wordfast.ini en-US>fr-FR F1:Help
Source entry Lock source case double-furnace boiler
Target entry
Lock target casechaudière à double foyer
Notea special type of boiler used in power plants.
F1 F2 F3
Lock source case
The Lock source case checkbox is unchecked by default. When checked, it renders terminology recognition case-sensitive.
Terminology Recognition is WFC's ability to 1. spot source glossary terms, or entries, in the currently opened source segment, and 2. highlight those terms in the source segment. This is generally not needed, and source entries are best entered in lower-case, unless case is an integral part of the source term.
The rare situations when this setting is needed is when source terms have different translations according to case.
The example below, although imperfect (the common noun wap could be written entirely in capital letters, although that is unlikely) will require two or three glossary entries, each with a checked Lock source case option:
Lock target case
The Lock target case checkbox is unchecked by default. When checked, it locks the target term's case when the target term is proposed in the course of translation.
In linguistics and dictionaries, the default appearance of terms is lower-case, except when case is a defining part of the term as in proper names, acronyms, etc. To summarize, a glossary, like a dictionary, generally contains lower case terms. With WFC, when you place terminology in the target segment, using the AutoSuggest feature or the Ctrl+Alt+Left/Right/Down set of shortcuts, WFC tries to replicate the source term's case to save time. This, of course, assumes that case generally follows the same principles in the source and target languages, which is not always the case.
Suppose your glossary contains a pair of source -> target terms such as summary -> résumé. You may have to translate various segments like:
Please send us a summary of your work.
Summary: see page 22.
3. SUMMARY
If the Lock target case checkbox is unchecked for that term, WFC will automatically adapt "résumé" to the source case, so it will correctly place "résumé" or "Résumé" or "RÉSUMÉ" depending on the source segment. WFC dresses up the target term's case in accordance with the source term's case.
There are cases, as in German, for example, where this feature is not recommended. Or when having terms whose case usually differs between two languages. Month and day names in English have an upper-case first letter (January, February...) while that is generally not the case in French (janvier, février - unless those start a sentence). This is when Lock target case comes handy for a glossary entry.
You can check, then right-click the Lock target case checkbox in the glossary entry dialog box to make it the default setting when adding terminology. That is recommended only if most of your terminology (like working into German) has a different case.
You can also enforce a glossary-wide, unconditional "Lock target case" by checking that same checkbox in the Terminology > Glossary setup. That glossary-level setting supersedes the entry-level setting. However, it is not a recommended setting.
Fields
The Terminology addition dialog box has three Fields that are made to receive codes or special mentions that do not belong in "Source entry", "Target entry", or "Note" fields.
Many translators add their own codes to glossary entries so they can later sort glossaries and extract selected terms.
For example, if you work on a project for a certain client, you may wish to add a client code to each glossary entry you create for this client, so that later you may distinguish them from other entries.
Since entering these codes is usually a repetitive task, two automatic features are added here:
| Code | Meaning |
| {DocName} | The current document's name |
| {DocPath} | The current document's path |
| {Today} | The current date |
| {User} | The current user's initials |
| {SrcLang} | The current source language TMX code |
| {TrgLang} | The current target language TMX code |
| {SrcTerm} | The term currently in the "Source" textbox |
| {TrgTerm} | The term currently in the "Target" textbox |
There are many other ways to add terminology. One way is to open the glossary with Ms-Excel, then type, or even copy-paste, rows and columns of data. Do not forget to close the glossary in Ms-Excel before using Ms-Word and WFC, because Ms-Excel keeps the glossary locked at all times when it is opened.
The Data Editor is also a way to manage and review glossaries.
Glossary format
A WFC glossary is a tab-delimited, text-only file containing 2 or 3 columns (source term, target term, optional note).
Additional columns can be present. Unicode text is accepted. "Columns" in a tab-delimited text-only file are items separated by tabulators.
If opened with Excel, the items in such a tab-delimited TXT file will be neatly distributed into columns.
If opened with Ms-Word, you would need to select the text and use the Table/Convert text to table menu to actually see items in a table format, with visible columns (but, before saving the text document, you would need to convert the table back to tab-delimited text).
Glossaries can be created or edited using Microsoft Excel.
The first column (column A) should contain source terms, the second column (column B) should contain target terms, the third column should contain notes, if any.
The Excel spreadsheet thus created should be saved as "Tab-delimited text" using Excel's File/Save as... menu.
Format when saving
If the glossary is a Ms-Word table, immediately before saving it, select the entire table (with the Table/Select table menu),
use the Table/Convert to text menu and convert the table to text, with the tabulator set as delimiter. Save your document as Text-only, or Unicode text if needed.
If the glossary is an Excel spreadsheet, save it as Tab-delimited text with Excel's File/Save as... menu.
The Tab-delimited Text format is selected in the "File type" drop-down option list.
Terminology format
Terms can use upper and/or lower case. Avoid unnecessary characters like brackets, quotes, slashes, dashes, etc. unless absolutely necessary.
The * (asterisk) wildcard can be used at the end of a term, if different endings of a term are possible (this is called MFTR and is described below). Here is a sample English-French glossary:
Maintenance* ↦ Entretien* Interview* ↦ Entrevue* minimum wage* ↦ salaire* minim*
Do not place the * wildcard less than four characters from the beginning of an entry. So pa* the bill* is not valid; use three entries like pay the bill*, pays the bill* and paid the bill*. However, if necessary, the * wildcard can be placed at the beginning of word - as the first character, for languages where the inflection is a prefix.
The combination of more than one wildcard in the same term is not recommended. It may produce unreliable results.
Multiple glossary entries
WFC accepts multiple glossary entries as follows:
avocat ↦ attorney avocat ↦ barrister avocat ↦ lawyer avocat ↦ avocado
etc.
Add {preferred} to either the Note field, or any of the three F1, F2, F3 fields to show WFC which entry is preferred when propagation is used.
FTR in WFC can be automatic (AFTR), or manual (MFTR).
MFTR is done by manually adding asterisk wildcards (*) at the end of words in the glossary so that most inflections of the glossary entry will be recognized in the document. For example, a glossary source entry like
Digital Analog* Converter*
will allow WFC to recognize, in the document, various approaching forms such as
Digital Analog Converters
Digital Analogic Converter
and more, if they are found in the source segment.
The asterisk can be placed inside a word. For example, the following entry, in the glossary:
Methyl*one
will match methylisothiazolinone, methylprednisolone, etc. It will not match methylisoline.
The pipe (|) can be placed inside a term, and is equivalent to an ending asterisk: anything after the pipe will be ignored.
The question mark (?) is a placeholder for any single character:
Methyl?one
will match Methyleone and/or Methylhone, but not Methylheone
The sharp sign (#) is a placeholder for any figure:
$#-fine
will match $200,000-fine or/and $200-fine.
Do not overload glossaries with common source language terms. Glossaries are meant to assist the translator with technical jargon, not with common languages. Glossaries are not a device to save typing.
AFTR is useful on raw glossaries, where the translator has no time to manually place asterisks as explained above. WFC uses various techniques that attempt to automatically make up for the possible inflections of terms found in the document's source text.
Note that glossaries can be hybrid: they can contain both AFTR (raw) and MFTR (asterisked) entries. If any entry has an asterisk, WFC will not attempt AFTR on that entry, but make use of the asterisk. If two entries match the same queried term, the MFTR entry will be chosen rather than the match brought up by AFTR. However, if an un-asterisked glossary entry perfectly matches a queried term (no AFTR neither MFTR needed) then of course this entry will prevail over all others.
WFC can use more than one glossary. This enables you to simultaneously use both client terminology, and your own terminology, in two distinct glossaries. You can even set color schemes to immediately spot from which glossary a term has been recognised.
Client terminology is usually rushed together with the job, and in some cases, it can even be rushed after the job started, by overworked project managers. Manually fuzzying-up a glossary takes time and is best done between jobs, on spare time, this is why AFTR is acceptable for rushed client terminology, in the heat of a live project.
AFTR attempts to recognize most inflections. AFTR is by nature an imprecise (fuzzy) process, and may bring up occasional mismatches, which should simply be ignored, or, if time permits, lead to manual fixing/fuzzying (MFTR) in the glossary. Here are a few observations:
The conclusion is that AFTR should not be attempted on large glossaries with many similar entries. And in no case can AFTR be used for saving typing time, "autoassembly" schemes, or be a substitute for machine translation.
Typical client-supplied terminology looks like this (target terms omitted):
two-way multiplexed autoresponder double-furnace boiler dichotomic search DOS-based application
etc. This is where AFTR really helps (complex specialist jargon), and yields best results. Once the job is completed, and you have a spare hour, you may consider integrating client terminology into one of your existing glossaries, and manually add asterisks as follows:
two-way multiplexed autoresponder* double furnace boiler* dichotomic search* DOS-based application*
etc. This way, your homegrown glossary runs on MFTR rather than AFTR.
The essence of AFTR is to determine what is a word's stem by gradually stripping letters from the word's end. Note that we deal here with statistics - there are exceptions to this rule, and every language has its requirements. The English verb go, for example, will change into went in the past tense, thereby defeating any AFTR attempt. By chance, client terminology is primarily made of technical words and expressions, where nouns outnumber verbs. Moreover, technical jargon (some of which is imported) is less prone to wild variations than literary language. Glossaries are primarily used for jargon, and more precisely, client jargon: the translator is supposed to understand common language.
How to load a glossary
Three glossaries can be selected in the WFC/Terminology/Glossary tabs.
Click the "Select glossary" button to find and specify the glossary you want to use (WFC glossaries ahve a TXT extension).
Then click the "Reorganise" button to have the glossary sorted and indexed by WFC.
You can view/edit the glossary with Ms-Word.
Using glossaries for QA
Check the appropriate option in the QA pane in WFC > Setup.
From then on, during a translation session, when the translator validates a translation, WFC will look for each source term in the source segment.
If a source term is found in the source segment, WFC will expect to find the corresponding target term in the target segment.
If it fails to do so, it will warn the user, giving a choice of editing the translation or ignoring the warning.
Select/deselect glossaries
Use the "Select glossary" button to select a glossary.
If you want to keep a glossary selected, but don't want this glossary to be active, i.e., if you do not want WFC to perform terminology recognition on this glossary, uncheck the "This glossary is active" checkbox. Otherwise, keep this checkbox checked. This checkbox is automatically checked each time you use the "Select glossary" button.
For propagation to occur, the corresponding Propagate command must be activated in Pandora's box.
Wordfast Classic wordfast.ini en-US>fr-FR F1:Help
Autosuggest synonyms
Add antonyms to synonyms.
Show synonyms/antonyms only when I press Ctrl+Down.
I don't use the thesaurus
If your version of Ms-Word has a thesaurus function for the target language you use, WFC can make good use of it. To check whether you have a thesaurus for your target language:
The thesaurus function can be useful to translators who engage in transcreation, or any form of creative literary translation, and who like to have a broad choice of terminology in the target language. Seeing a broad array of synonyms can stimulate the mind into finding a term that fits the situation. In literary translation, TMs and glossaries are of limited use, but the help of a thesaurus in the target language can be useful.
One issue with Ms-Word's thesaurus is that it's a pull feature. In other words, you need to do an action (use a shortcut, or click an icon) to get to the list of synonyms for a selected word. WFC changes this "pull" behaviour to a more productive and comfortable "push" mode. Any time you finish typing a word in the target segment, with the cursor at the end of word, WFC will pop down a list of synonyms. You can then replace your last typed word with one of its synonyms very easily.
To ensure compatibility with older versions of WFC, it is possible to disable the thesaurus feature, and use a third glossary instead. This becomes possible only if both a first and a second glossary are already selected. To replace the thesaurus with a third glossary, click the "I don't use the thesaurus" checkbox and immediately select a third glossary. Note that even in that mode, pressing Ctrl+Down on a word brings up synonyms - in a "pull" and unobtrusive mode.
To re-enable the thesaurus feature, remove the third glossary.
Wordfast Classic wordfast.ini en-US>fr-FR F1:Help
This blocklist is active
Current blocklist:
C:\wordfast\myBL-EN2FR.txt
Number of entries: 34
File size: 2 Kbytes
Date: 2016-01-15 at 18:19:06
WFC can check target segments for unwanted words or expressions. As for the glossary feature, the check is not case-sensitive and the * wildcard can be used to end a word. The format is Text-only, in two columns. The second column can be left empty; as an option, it can contain the recommended term that should replace the blocklisted term. There is no AFTR on blocklists.
Wordfast Classic wordfast.ini en-US>fr-FR F1:Help
Current F-R list:
C:\wordfast\myFR-list.txt
Number of entries: 20
File size: 1 Kbyte
Date: 2016-01-15 at 18:19:06Confirm all Find-replace actions
Do not confirm Find-replace actions
The F-R (Find-Replace) list contains entries (lines) that make WFC execute series of Find-replace actions:
F-R commands are useful for Quality Assurance purposes, verification, document repair, etc. The versatility of Ms-Word's Find-Replace facility makes this feature very powerful, and practically unfound in other translation tools.
Note: The Find-Replace (F-R) actions are limited to non-hidden text. In a segmented document, source text and delimiters have a "hidden text" attribute.
Individual entries (lines) of the F-R list are created or edited in the Data Editor.
A note (comment) field is offered to comment the line. The next three columns are used to activate three standard Ms-Word Find/Replace switches: the /wc switch turns on the Use wildcards option, the /mc switch turns on the Match case option, the /ww switch turns on the Whole word option.
The /confirm switch, if present in the Note field switch, prompts the translator for a confirmation before the replacement is done.
The "Confirm all Find-replace actions" option forces F-R confirmation, whatever switch, or absence thereof, is in an F-R list entry.
The "Do not confirm Find-replace actions" option prevents F-R confirmation, overriding whatever switch is in the F-R list entry. But be very cautious with this setting!
You can add basic formatting options to the Find or the Replace fields, such as +{tw4winInternal}, which will be interpreted as a "tw4winInternal" style in the Find or Replace argument. Likewise, +{<b>}, +{<i>}, +{<u>} will be interpreted as bold, italic, or underlined font attributes.
Refrain from having hundreds of active F-R lines at any given time: do not use F-R as a substitute for machine translation, text processing, saving keystrokes, etc.
The F-R feature is offered when nothing else will help.
F-R is mostly used to save a document after translation, requiring many Find-Replace operations. In this case, it is used from Tools > Misc > batch Find-replace.
Thoroughly test your F-R parameters (using Ms-Word's Find-replace dialog box) on a test file. F-R can backfire. The sample list which is provided when you create a new Find-replace list in the WFC user interface under > Terminology > Find-replace contains a few examples. Here are a few more examples:
Replace <Tag1> with <Tag2> - but only if they have the tw4winInternal style:
Find: <Tag1>+{tw4winInternal}
Repl: <Tag2>+{tw4winInternal}
How to make sure the target segment has no more than 100 signs or characters, including spaces:
Find: ?{100}
Repl: [leave empty]
Switch: /confirm /wc
Reverse "David John" into "John David":
Find: (John) (David)
Repl: \2 \1
Switch: /wc
Replace endashes (-) and emdashes (-) with simple dashes (minus signs, -):
Find: [^0150-^0151]
Repl: -
Switch: /wc
Force a non-breaking space before :;!? in the target segment (two passes):
Find: ([a-z,A-Z,0-9]) ([\:\;\!\?])
Repl: \1\2
Switch: /wc
Power users can execute the Find-Replace list over an entire document. Use WFC's Tools > Misc > Batch Find-replace to run this powerful feature, for example, on multiple documents. Note that Find-Replace actions are very powerful tools, but can be destructive if the list of F-R actions has not been carefully created, and thoroughly tested. Use extreme caution, and thoroughly test on a copy of a document.
Wordfast Classic wordfast.ini en-US>fr-FR F1:Help
External dictionaries: Right-click on a source term brings up the following web glossary: http://iate.europa.eu/SearchByQuery.do?method=search &query= Reference search folders (Ins/+ to add, Del/- to delete) C:\wordfast\reference
Select Dictionary (Windows only): WFC can be linked to external dictionaries. You can select an external dictionary application (like Trados MultiTerm™, the Harrap's Shorter™, the Collins™ version 100, Microsoft Encarta™, etc). The Keys button is used to define the keystrokes used to interrogate the dictionary (see the Dictionary section below for details). During a translation session, or at any other time, place the cursor on a word, or select an expression, and press Ctrl+Alt+D or click the Dictionary icon.
Reference
A reference search is like a concordance search, but it is done on any sort of documents (not only TMs).
The Ctrl+Alt+N shortcut or the 🔍 icon launches the Reference search from within the document you translate,
just like Ctrl+Alt+C launches a concordance search.
The material is usually of monolingual content.
The following formats can be searched by WFC: DOC, RTF, TXT, HTML, SGML, XML, MIF, CSV.
Other formats need to be converted to a text format.
Rules for searches are the same as for Concordance search (see above).
All Pandora's box commands concerning the behaviour of the Concordance window apply to the Reference window.
WFC will run the reference search on all files present in the folder(s) specified for reference material.
As with Concordance search, it is possible to use the Escape key (or the same shortcut, i.e. Ctrl+Alt+N) to cancel a search.
Use the Insert (or +) key or the Delete (or -) key to add or remove folder(s) where the "raw material" for Reference search is located.
Wordfast Classic wordfast.ini en-US>fr-FR F1:Help
Search Concordance in TM
Search in all sibling TMsSearch Concordance in BTM Search Concordance in Remote TM Hide Concordance headers (TU properties) Maximum Concordance results: 50
In a document, Concordance searches the Translation Memory (TM) for Translation Units (TUs) that contain a given word or phrase. This is precious to see terminology both in context, and in bilingual form.
You can specify which TMs are searched for Concordance.
Search in all sibling TMs. With this option, concordance searches extend to other TMs present in the same folder as the currently active TM.
Hide Concordance headers (TU properties). This options simplifies the display of results by hiding the top information on each TU property. It lets you sift through data faster.
Maximum Concordance results: limits the number of hits that are returned. Avoid a large number, as WFC can be overhelmed by too many hits. Values range from 10 to 500.
In a document, you can launch a Concordance search using the Ctrl+Alt+C shortcut or the Concordance icon 🗘:
Concordance search
Exact match Source only ▼ Skip this dialog
For simplicity's sake, WFC follows the common rules used by major search engines. Therefore:
Note that to open the dialog box as above, you must start concordance search when no selection is made; if a selection is made, WFC assumes that the selected text has to be searched and will directly search for it, without showing the extended search dialog box. This allows fast searches with minimal clicks or shortcuts.
The same rules apply for Reference searches as well.
It is possible to cancel a long Concordance search with the Escape key
Wordfast Classic wordfast.ini en-US>fr-FR F1:Help
Yet another document.docx
Deliverable document.docx
document footnotes headers/footer frames To browse files on disk: close all documents. Right-click: (un)select all.
Before tools are used, the files on which they are used must be selected.
When starting WFC, if documents are already opened in Ms-Word, they will appear in the "Selected files" list. Otherwise (no document opened in Ms-Word when you start WFC), the files present in the current folder are listed. Click the "browse" button to change folder if needed.
Checked files are processed; unchecked files are not processed.
Clean-up deletes all segmentation marks and source segments from the selected files, leaving only the translated text. This is the final step in a translation process, unless the client, usually a translation agency, specifically requires a segmented (bilingual) document. The TM is updated if the target segment has been manually edited after it was created. Manual edition means you edited the segment without actually opening it, or without WFC interaction, or using a different TM.
Note: the Quick-clean icon in the WFC toolbar lets you clean up a document much faster, but without updating the TM, and without producing a report.
Analyse gives an analysis of selected document(s) before translation, reporting the number
of segments and words, with the match ratings of the segments in relation to the current TM.
If the document is already translated and segmented, Analyse will not be carried out.
The analysis report created after analysis details the following points:
|
Repetitions refers to repetitions found within the document(s) that was/were analyzed (this does not concern the translation memory). For example, if a same sentence (segment) appears 3 times in the set of analyzed documents, the repetition counter will show 2 repetitions.
Match rate per percentage: this is a comparison made between the segments that are found in the documents and any source segment found in the translation memory that WFC deems analogous.
Segments reported in the "100% category are not always perfectly identical. In that case, a 100% match is "considered" as such by WFC. WFC may have to overlook case differences, differences in quotes/apostrophes styles, and more important, differences in tags or numbers. WFC computes a sophisticated substitution of numbers, or tags, or quotes, or apostrophes, in order to justify its claims. When the substitution is not totally reliable, WFC makes every effort to detect the ambiguity, and presents the purported "exact match" against a yellow background to raise the translator's attention.
TM rules can be used so that WFC enforces a more strict definition of what a 100% match is.
Note that all character counts include spaces.
! The word count does not include untranslatable elements. Isolated numbers, figures, fields (which would constitute a segment on their own) are not included. To include those, add "SegmentAll" to Pandora's Box, and make sure that it is enabled.
If you still see a notable discrepancy with other translation tools, make sure the methodology is the same. Under the Tools tab, the fact that headers, footers, notes, are included, or not included, can also play a role.
See the section on Wordcount for more information on this crucual issue.
Translate pre-translates the selected document(s), with the use of the current translation memory. Unknown (no-match) segments will be copied over the target segment if you specified "CopySourceWhenNoMatch" in Pandora's box. However, if a link with a machine translation program is activated (see MT), unknown segments will be machine translated.
Once pre-translation is done, start a regular WFC session and translate your document(s) as usual. Work will be faster, because segmentation and matching have already been done. When cleaning up such a document, use the regular clean-up tool, and answer "yes" at the question "Update translation memory?".
Quality Assurance performs a quality assurance scan & report on all selected files; a detailed report is given for each file, with an overall summary of QA errors found on all files. Set up the required QA options in the WFC/Setup/QA check tab before running this tool.
Extract opens all selected documents and extracts all segments into a text document named "WfExtracted.txt". This document in text mode is presented to you so you can save it under a different name and/or folder if needed (save the document as Unicode if your language requires unicode).
The Extract tool also produces a second file named WfRepetitions.txt, located in the same folder as WfExtracted.txt, which contains all segments that were found repeated more than once. This allows a project manager to have repetitions translated before the project starts, and to add these translated repetitions to the TM being distributed to translators. This method ensures consistency across the project, and further cost-cutting.
Misc
PDF/Web Text Rebuild
Translators often receive badly formatted Ms-Word "DOCX" documents, which are the results of a conversion from an alien format like PDF, HTML (web) documents, PowerPoint, etc.
In those documents, lines may end with a "hard" return, breaking paragraphs into multiples lines. The "Rebuild" tool attempts a reconstruction of those broken paragraphs.
! Remember to always process a copy of a document!
This feature also reduces unnecessary formats such as backgrounds, wild font sizes (it simplifies all font sizes: to size 8 if smaller than 9, to size 14 if larger than 14), and extreme paragraph formatting (skinny columns are merged, etc.).
Please consult with your client before using this feature:
Batch find-replace
This function uses the F-R (Find-Replace) list found under the Terminology tab, and accessible in the Data Editor. All checked items in the F-R list will be used as Find-Replace on the selected documents. Warning! Only process copies of documents. Thoroughly test your find-replace list.
Wordfast Classic wordfast.ini en-US>fr-FR F1:Help
Source segment color=9 (Dark blue)
Fuzzy target segment color=0 (No color)
100% target segment color=0 (No color)
Unknown target segment color=0 (No color)
Insert the following character(s) after segments=
Protect delimiters=1 (Regular)
Separators for thousands, decimals, date (target language)=
Alt+Enter=1 (Expand to end of paragraph)
wordfast.ini | ▼
Click the relevant line, then press Enter on the option to create/edit/delete the value. Or simply double-click the relevant line.
End of Segment Punctuation=. : ? ! ^t ^l
Enter or edit the End of Segment Punctuations (ESPs) that end a sentence. Default values are strongly recommended.
The default setting is . : ? ! ^t ^l , where ^t means tabulator and ^l manual line break.
If an ESP is found, the segment will continue if what follows the punctuation is a lower-case alphabetical letter
(or some numbers or punctuations that are considered as usually not ending a segment).
See the rules in the Segments section to alter that behavior, but note that those rules must be used sparingly.
Note: if your setup contains a double punctuation (for example, two colons rather than just one), this forces WFC to cut (halt) segmenting at that punctuation, regardless of what follows.
Example: . :: ? ! ^t ^l
Warning on segmentation.
No amount of artificial intelligence will ever get segmenting right all the time in all situations, in all languages.
You must be ready to liberally use the Expand and Shrink segment shortcuts or icons to correct the machine's segmentation.
The rules offered herewith are proposed with no guarantee that they will segment right all the time. Just as with self-driving cars: keep your hands on the steering wheel!
Target segment font
Defines the font used for target segments. This is particularly useful when the target segment cannot use the same font as the source document,
like translating from English to Russian, French to Greek, Italian to Hebrew, Chinese, etc.
Colors
These values will set up colors that will be applied to the segmented text, at validation time.
These colors will be reset to the default ("Auto") color at clean-up time.
Whoops - If you started to translate with colors set, and realized after a few segments that you should not have used colors at all
(as this is the case if the source text has colors that have to be preserved in the translated text), please note that, at clean-up time,
WFC will reset the cleaned, target text to the "Auto" color, which appears black on most systems.
In such a case, enter the LeaveColors command in Pandora's box to instruct WFC not to reset colors after clean-up.
Insert the following characters(s) after segment=
This option sets the characters, or short text, which can be added right after every segment.
Note the following convention for specifying some special characters:
Unicode values are also accepted (ranging from 256 to 65535).
{space} space {tab} tabulator; &'AA; any character where AA is the hexadecimal code of the character; example: &'AB; for ANSI 171 � any character where 00 is the decimal code of the character; example: « for ANSI 171
Separators for thousands, decimals, date
Those separators should be automatically set by WFC based on your target language, but can be modified here if needed.
Alt+Enter
Alt+Enter is normally used to expand the current segment to the end of the current pararaph.
Alt+Enter can be re-assigned to replace Alt+Enter
(for example, when the Editor/Spell-checked pane is active, and uses that shortcut).
Reset
Will reset all settings to WFC's default values.
Reverse all
Reverses the Translation Memories (TM and BTM), as well as the glossaries, in one pass. Note that TMs and glossaries are reversed, keeping their own names: original files are rewritten.
If you need to keep a version of those files before they are reversed, you must manually back them up.
Save setup as...
Saves the current setup to an INI file. Ini files are saved in the same folder as the folder where Wordfast.dot is located.
This folder is usually Ms-Word's startup folder (If you cannot locate your Ms-Word Startup folder, see the note on hidden folders).
Using the browse... option lets you open an ini file anywhere, including network folders or floppy disks.
Wordfast Classic wordfast.ini en-US>fr-FR F1:Help
An ESP without a trailing space ends a segment.
An ESP + a space + a lowercase end a segment.
Tag bookmarks before translation
Use Double Strikethrough as untranslatable attribute.
Use Hidden text untranslatable attribute.
Apply Word's AutoCorrect / AutoFormat to target segments.
AbbreviationsCorp.,Dec.,Dept.,Dr.,D.C.,e.g.,etc.,Jr.,Inc.,i.e.
Set target segment language to TM's target language
WFC's QA options can require that the target segment be spell-checked before validation.
If you select this option (the default one), WFC will apply the current TM's target language to each target segment
(just as if you were opening the Tools/language... menu and applying a language to the target segment yourself),
so that, if spell checking is done, the right language is used.
Set target segment language to Word's default language
If your target language is not in WFC's list of languages, or if for some other reason WFC cannot recognise your specific language,
select this option, get back to Ms-Word, set the target language as default language in Ms-Word (menu Tools/Language):
WFC will apply that default language to target segments. If you select "leave unchanged",
then WFC will not apply a language definition to the target segments during sessions.
See Appendix II for a brief discussion on this subject.
A number + an ESP end a segment
Normally, WFC will not consider a number followed by an ESP as ending a sentence.
Checking this option will disable this rule.
An ESP without a trailing space ends a segment
Normally, WFC will consider an ESP as ending a sentence only if it is followed by at least one space.
Checking this option will disable this rule.
An ESP + a space + a lowercase end a segment
Normally, WFC will consider that an ESP followed by a space followed by a lower-case letter do not end a sentence.
Checking this box will disable this rule.
Tag bookmarks before translation
When a translation session begins on a document that contains bookmarks,
this will pop up a reminder that special steps must be taken to have bookmarks tagged before the translation process
and that bookmarks must be transferred to the target segment during the translation process.
Use DoubleStrikeThrough as untranslatable attribute
This is a DoubleStrikeThrough text example..
See the note on text exclusion for more information.
Apply Word's AutoCorrect / AutoFormat to target segments.
WFC can perform an AutoFormat series of corrections to any text that WFC introduces in your target segment (rather than text you type).
The AutoFormat corrections are set up in Ms-Word's Options > AutoCorrect section, under AutoFormat.
They are limited to quotes, dashes, and apostrophes.
They are applied to TM propositions, glossary items, or placeables, at the moment WFC places them in the target segment.
Please note that this feature refers to the AutoFormat feature in Ms-Word's options, not to AutoCorrect.
AutoCorrect can be activated in Ms-Word, but it applies to what you type, not to what WFC pastes in your target segment.
Special case: You can execute Ms-Word's list of AutoCorrect's "Search for / Replace with" substitutions on text that is introduced by WFC
(TM propositions, glossary items, placeables).
To do this, have the "Search for" text begin with an exclamation mark !
So, if your AutoCorrect list contains
| Replace | With |
| !recognision | recognition |
| !partision | partition |
WFC will replace recognision with recognition, and partision with partition.
! Note: Ms-Word's AutoCorrect and AutoFormat settings are defined per language. Whenever you set AutoCorrect, ensure that the current selection has the proper language prior to opening Ms-Word's AutoCorrect dialog box. A text's language is an attribute just like Bold, or Italic, except that it's invisible -- but it appears in Ms-Word's status bar. While most translators open text in their source language, AutoCorrect should be set on a document, or a selection, with text marked as target language.
Abbreviations
Enter the most common abbreviations in your language. WFC will not end a sentence at a word belonging to this list. Separate abbreviations with a comma:
D.,Dr.,M.,Mr.,Mrs.,P.,Pr.,Pres.,i.e.,Corp.,
Remember that the Expand function can expand a segment to fit the actual sentence, even if an unknown abbreviation ends the segment too soon,
and that Shift+Alt+Down will force WFC to segment the text you selected.
An abbreviation must have less than 16 characters.
Wordfast Classic wordfast.ini en-US>fr-FR F1:Help
Quality assurance options: QA in companion
Check terminology from Glossary#3
Check blocklisted terms
Run the Find-replace list on translations
Find typos in proper names
Warn if character count in target>80
Warn if ending punctuation is different in target
Warn if source/target ratio is >=2
Enforce a strict numeric Untranslatable' definition
Enable QA on already-translated segments
QA in companion
This option works if a "QA companion" is currently opened. It is a lot less intrusive than the regular QA method, which flies an alarm for each and every purported QA item.
As with all language-related automations, QA alarms may produce "false positives", or alarms that are not necessary. Having to acknowledge every one of those alarms every time a segment is committed can lower productivity.
As opposed to the above, QA in companion displays all QA items in a side window, in real-time, as you type your translation. If all goes well, when your target segment is complete, the QA companion should show a message like "No QA warnings". If there are any alarms left when you commit the segment, no pop-up messages will be raised, because alarms are visible in the companion. This is less intrusive, but requires more attention.
To open or close a QA companion, double-press Ctrl+Alt+Q: keep Ctrl and Alt pressed down, then hit Q twice in a row, at the speed of a mouse double-click, then release Ctrl and Alt. You may need to repeat this if it does not work the first time.
Quality assurance options
This part of WFC is used to set up the actions performed during quality assurance.
If QA is activated during translation, target segments are QA'ed before validation (this is the real-time mode), i.e., immediately after the user has pressed "NexSegment", but immediately before the segment is stored in the TM.
Remember that you can associate your own macro to QA, by entering it in Pandora's Box MacroQualityAssurance command. See Appendix III for examples.
If Quality Assurance is started outside a translation session:
In both cases: if the cursor is in the first sentence of the document, WFC will ask whether you want to QA the entire document and produce a report, or QA one segment at a time, stopping at every problem so that you may correct errors step-by-step. If the cursor is not in the first sentence of the document, the second option (step-by-step QA) will be assumed.
Spell/grammar check are available only in real-time Quality Assurance mode (during translation sessions), but not in batch mode, when a report has to be produced.
Check terminology from Glossary #1, 2, 3
This option lets WFC monitor the use of terminology in the translation process. If glossary terms are found in the target segment, the corresponding target term (or at least one of the target terms when one source glossary entry has multiple translations).
Check blocklisted terms
This option lets WFC monitor the target segment to make sure no blocklisted terms are used.
Run the Find-Replace list on translations
WFC can maintain a list of find-replace actions to be performed on target segments when translations are committed, usually right before moving to the next segment. Find-replaces are equivalent to a manual use of Ms-Word's own "Find-replace" dialog box.
The Find-Replace operation is executed on:
Find typos in proper names
This features attempts to spot proper names in the source segment, and verifies whether they are found "as is" in the target segment. False positives are rare but possible. This feature should not be used with languages that inflect or modify proper names.
Warn if character count >=N
WFC can ensure that the length (in characters including spaces) of the target segment is not greater than a given quantity
Warn if ending punctuation is different in target
WFC can ensure that both source and target segments have the same ending punctuation. This is useful to verify that the ending punctuation is not missing in target segments - a common typo.
Warn if source/target ratio >=N
This verification will statistically detect possible cases where the target segment is empty, or nearly non-existent.
Warn if first source/target letters have different case
This verification will statistically detect cases where the first letter in source and target segments have a different cases. It is mostly used to detect a missing uppercase initial letter when it should be expected. False positives are rare, because the source segment is taken as clue to the expected target initial letter case.
Source untranslatables must be found in target
Untranslatables are figures (any combination of figures and letters, or any contiguous series of figures and letters, are considered as untranslatables). URLs and email addresses, as well as fields (to the exception of index fields and hyperlinks), are also considered as being untranslatable. WFC can ensure that all source untranslatables are found in the target segment.
Target untranslatables must be found in source
Same as above - but this time, the other way.
Source tags must be found in target
WFC can ensure that source internal tags are found in the target segment.
Target tags must be found in source
WFC can ensure that target internal tags are found in the source segment.
Identical bookmarks
WFC can check whether there is the same number of bookmark markers (brackets like [ or []) in source and target segments. This is useful when the client wants source bookmarks to be transferred into the translated text. If bookmarks must be preserved during translation, please refer to the special section on bookmarks.
Enforce a strict numeric "Untranslatable" definition
QA attempts to spot discrepancies in source/target numbers. A "number" or "numeric placeable" here means any series of characters that contain at least a number. The problem is that translation may alter those numbers (23rd turning into 23àme, or 23ste), so that QA will bring up "false positive" warnings. Without this option, both 23 and 23rd will match 23, 23àme, and 23ste. With this option checked, 23 will ony match 23, and 23rd will only match 23rd.
Enable QA on already-translated segments
This option will force WFC to QA existing segments. That may be necessary when working on a document that has been already segmented by the client. In other cases, systemically running QA when reopening an existing segment (which has been already translated and already QAed) can slow down WFC.
Wordfast Classic wordfast.ini en-US>fr-FR F1:Help
Large Wordfast dialog boxes
Remember Wordfast setup tab position
Notifications= 1 (In segment, full)
Toolbar size=1
Glossaries under toolbar=0
Segment color scheme=1 (Regular)
Minimalist segment for screens < 15-inch
This dialog box is used to optimize Ms-Word's view and display parameters when translation begins, to ensure a comfortable visual environment. Do not underestimate this part. Visual strain coming from a mediocre work setup takes its toll on translators. Unfortunately, it can take years before one realizes the strain he/she has put on his/her eyes. The following parameters will setup your display and view environment every time you start a translation session.
Hide ruler
In most cases, the ruler is not essential, but takes up space, which is a problem on small screens. Override this if required.
Wrap text to window
This feature is essential (but available only in normal view) to avoid scrolling horizontally every time a line is wider than the screen.
Large Wordfast dialog boxes
This is useful with very high-resolution screens of a small physical size.
Remember Wordfast setup tab position
Opens the Wordfast setup on the same tab as the last time.
Notifications
Notifications are messages about the various translation units, the nature and origin of recognized terminology, etc.
Unchecked: no notifications.
Checked: notifications are:
Toolbar size
Double-click this option, or select it (click on it) then press Enter to change it.
Wordfast
Toolbar size
1=Regular
2=Wide
3=Mini
Optional switches: /float /notips
When the mouse hovers over the toolbar's last icon, the hamburger menu ☰ , the toolbar expands to its full width. It automatically shrinks after a few seconds.
Mini is preferred by minimalists who know the shortcuts which perform icons' tasks, like
Ctrl+Alt+C for Concordance, etc.
Since translators' hands spend more time on a keyboard than a mouse, using shortcuts is recommended.
Note that there are far more features and commands in WFC, which you can access by clicking the very last icon (the "hamburger" menu), selecting an option, then pressing Enter.
Switches, if used, are entered right after the number:
Glossaries under toolbar
Sets up whether glossaries (the first 10,000 lines) are shown in a drop-down list under the toolbar.
If this setting is used, enter up to three glossaries, identified by their number, e.g. "1" or "1,2", or "1,3" or "2,3" or "1,3", etc.
Segment color theme
Choose between 1 (Regular), 2 (Pastel -- light colors, less agressive), 3 (Transparent), or 4 (Minimalist, not recommended).
Remember that you can manually modify your display Word options during a translation session using Ms-Word's own Options/View preferences (Or Preferences/View with most Macs).
Note that WFC forces the display of hidden text, because using WFC without hidden text visible can be dangerous, since delimiters would be invisible and easily deleted.
Minimalist segment for screens < 15 inches.
When using a laptop with a rather small screen, there is limited vertical space to display a full segment.
"Minimalist segment" only keeps essential information displayed: source segment, target segment, a maximum of four lines of AutoSuggest.
This helps ensure that the full segment is visible, even if vertical space is scarce. Please note the following space-saving tips when working on a laptop screen:
Press Ctrl+F1 on Word 2007 and later to toggle that thick ribbon on or off as needed.
Use the View/Toolbar menu on pre-2007 Ms-Word versions to hide the toolbars you do not use.
Here is a minimalist segment without the display of TM above it, without TM information between source and target, and 4 lines of AutoSuggest. The same "non-minimalist" segment could be up to twice the vertical size:
| |||||||||
Note: this minimalist view is automatically used when a segment is opened in a narrow table cell, in a footnote, and endnote, a header, or a footer.
Reset mutable warnings
This button only appears if you have muted at least one mutable warning.
Mutable warnings are messages or warnings that have a Do not show again checkbox as here:
Wordfast Classic
Some message or warning here!
Do not show again
Wordfast Classic wordfast.ini en-US>fr-FR F1:Help
Subsegments from Machine Translation
Terminology from Machine translation
Conversions US > Metric
Show source terms
Prefill target with top match. Order of preference: RT,MT,BT,TM
AutoSuggest (AS) suggests TM matches and placeables in a drop-down list. See the section on placeables for more context.
You can continue typing and ignore the suggestion, or press Enter to "place" the suggestion. Suppose the source segment contains proper names like "Zbigniew Brzezinski" or "Grossbliederstroff": AS will suggest those names as soon as a capital Z or G is typed. Speed and reliability are the two advantages of AS.
TM and MT propositions are suggested at all times, as well as the most common placeables. The definition of "placeables" can be fine-tuned for special situations: see the section on placeables.
Subsegments from Translation Memory
Subsegments from the TM will be proposed whenever possible.
Subsegments from Machine Translation
Subsegments from MT will be proposed whenever possible.
Conversions
This powerul feature autosuggests conversions (US to metric, ot vice versa is applicable) if a unit of measurement follows them.
Show source terms
This adds the glossary's source term in the AutoSuggest drop-down to provide better control and context (but may be a distraction).
Prefill target with the top match
This option pre-fills the target segment with the highest-rated match, among all available sources: TM, BTM (BT), Remote TM (RT), and Machine Translation (MT). Note that if a remote TM is used, and the remote TM needs a delay to respond, this option will wait for the reply from the remote TM. Also note that a proposed translation will be pasted (prefilling the target segment) only if the target segment is empty.
Order of preference
This option specifies the order for translation propositions in the AS dropdown (it has no effcet on placeables, only on target segment propositions).
Wordfast Classic wordfast.ini en-US>fr-FR F1:Help
Enable PB
Commands are case-sensitive. Commands that contain an underscore are disabled, like Need_ForSpeed.Auto_Complete=NoHeaders
Allow_EmptyTarget
CleanUp_OnlyBookmarks
ConcordanceCloseAfterCopy
Concordance_MaxHits=10
WFC tries to cover the essential needs of everyday translation, but there are countless special situations that require specific features. Rather that multiplying endless setups with buttons and checkboxes, a raw but efficient "un-natural" interface is used to activate some rarely used features. Just enter one of the following commands in Pandora's box, to obtain a particular behaviour from WFC. Commands are separated with a paragraph mark (use Shift+Enter to enter paragraph marks).
Important: PB commands are case-sensitive: use them the way they are produced when clicking the "Commands" button, or the way they are written in this manual. Adding or removing the _ (underscore) character makes them inactive or active. The underscore character can be located anywhere within the command. Thus,
AllowEmptyTarget is active;
Allow_EmptyTarget is not active;
AllowEmpty_Target is not active;
_AllowEmptyTarget is active because the underscore is not within the command;
Allowemptytarget is ignored because its case is not correct.
Right-clicking the list of commands will toggle between the display of all commands, and only active commands.
The syntax of these commands is complex. Thus, rather than writing them into, and deleting them from, Pandora's box, you may consider leaving them in Pandora's box. To turn off a command, just insert an underscore in the command. In other words, SegmentAll is active, but Segment_All is not active. The underscore can be positioned anywhere inside the command.
| AncillaryFiles=KeepWithParent Ancillary_FilesFolder= | Ancillary files are non-critical files that are generated by WFC for every TM or glossary. Those are indexes, or backups. By default, these files are kept in the same folder where wordfast.dot resides (usually, Word's STARTUP folder). You can opt for having those files in the same folder as their parent files. AncillaryFilesFolder= will specifiy a custom folder for ancillary files. |
| AllowEmptyTarget | Allows WFC to validate a segment with an empty target. Empty targets do not pose any particular problem, but in regular mode (especially for beginners), there's a warning that prevents the user from validating an empty segment. |
| ConcordanceCloseAfterCopy | Closes the concordance search window when you use the Alt+F12 shortcut (copy-paste into target segment). |
| CopySearchWord | Copies into the clipboard the term that is selected for search when a Concordance or Reference search is done. |
| CopySourceWhenNoMatch | Is equivalent to using the Copy source icon in WFC when no match is proposed by the translation memory. |
| DoNotMonitorKeys= | Possible values (comma-separated, case-sensitive): Escape, Enter, Delete, Backspace, Ctrl+A, Ctrl+V, Ctrl+X, Home, End, PageUp, PageDown, KeyUp, KeyDown, KeyRight, KeyLeft. See the section on protection for more information. |
| FirstKeyControl FirstKeyShift |
With some versions of Ms-Word 2003, the very first character typed after a segment opens is "mute". Enable any of these commands (only one at a time) to cure the problem. They simulate the press of a "mute" key to work around the problem. |
| FirstKeyDNS | Solves a problem caused by some versions of the DNS dictation software that makes the cursor jump a few lines up or down after a segment opens. |
| GlossaryXColor | (where X can be 1, 2, or 3). Possible values are blue, green, gray, yellow, pink. Thus, Glossary2Color=yellow will result in WFC highlighting recognised terminology from Glossary #2 in yellow. |
| KeepTemplate=addin.dot | When you expand the WFC template, WFC de-activates any template or add-in found in Tools/Templates & Add-Ins. Many templates have shortcuts or macros that conflict with WFC's. If you want to keep a template which can work together with WFC, enter its name. The example provided here would keep the template named "addin.dot" active together with WFC. To keep all templates, use KeepTemplate=All. This setting, however, may cause problems with templates that rely on shortcuts used by WFC. |
| LeaveColors | At clean-up time, if colors were specified in WFC/Setup/General, colors are reset by applying the "Auto" color to the entire document. This option inhibits this general color reset. |
| LinkSetupToDocument | It is possible to link documents (but only documents of Ms-Word's native format DOC ) to a particular setup. If this is done, and a later translation session is opened with a different setup, WFC will issue a warning. This warning gives you the choice of using the new setup (the document's link will then be modified accordingly), or loading the original setup. The same warning will be issued at cleanup time, on some conditions. Use the WFC menu option "Unlink" on a document to unlink it, or "Relink" to re-link it. See the important note below. |
| LinkTMToDocument | It is possible to link documents (but only documents of Ms-Word's native format DOC ) to a particular TM. If this is done, and a later session is opened with a different TM, WFC will issue a warning. This warning gives you the choice of using the new TM (the document's link will then be modified accordingly), or loading the original TM. Use the WFC menu option "Unlink" on a document to unlink it, or "Relink" to re-link it. The same warning will be issued at cleanup time, on some conditions. |
| ! Note on the "Link" settings. | The "Link" feature stamps documents with a marker that links them to a TM or Setup, when opening a translation session. Any WFC, with any setting (even if the two "Link" setting are not checked) will issue a warning if another translation session is started on the linked document with a different TM or setup. Cleanup, however, will issue a warning only if the WFC/Tools/Cleanup button is used and "Update TM" is required and the corresponding WFC "Link" setting is currently checked. In other words, a linked document will trigger a warning at all times when starting a translation session, regardless of the local and current WFC setup, but the same document will trigger a warning at cleanup time only if the local and current WFC setup's "Link" option is checked. The reason is that many translators translate, but send uncleaned documents to the client or agency, and the cleanup is performed there. This prevents cleanup on a different computer (like the client's or the agency's) from triggering the warning. |
| MacroEndSession=XXX | Where XXX is an Ms-Word macro name. The EndSession macro is executed when a translation session ends, with Alt+End, or when closing a segment in any other way. |
| MacroPreSegmentation=XXX | Where XXX is an Ms-Word macro name. The PreSegmentation macro is executed when a segment is opened, right before the segment is turned over to the translator for translation or edition. See Appendix III for more info on macros. |
| MacroPostSegmentation=XXX | Where XXX is an Ms-Word macro name. The PostSegmentation macro is executed when the translator "closes" a segment, immediately before closure. "Closing" a segment happens if you press Alt+Enter on an opened segment, or Alt+Up, or Alt+End, or any other shortcut that closes the currently opened segment. That macro us typical meant to check for errors and warn the user. See Appendix III for more info on macros. |
| MacroMaiden=XXX | Where XXX is an Ms-Word macro name. The Maiden macro is executed only once, the very first time a WFC translation session is started on a document. If your macro ends with a Visual Basic "End" instruction, this will also halt the WFC translation session opening, and the document will remain "virgin". Running the WFC menu "Misc/Unlink" option renders the active document "virgin" again. See Appendix III for more info on macros. |
| MacroRetire=XXX | Where XXX is an Ms-Word macro name. The Retire macro is executed right before a clean-up is attempted on a WFC-translated document. See Appendix III for more info on macros. |
| MacroStartSession=XXX | Where XXX is an Ms-Word macro name. The StartSession macro is executed when a translation session begins. |
| MacroQualityAssurance=XXX | Where XXX is an Ms-Word macro name. The QualityCheck macro is executed right before a MacroPostSegmentation, that is, when the translator closes an opened segment (by using Alt+Enter, Alt+Up, Alt+End, or any other shortcut that closes the currently opened segment). See the note on QA macro interactive mode. See Appendix III for more info on macros. |
| NoPrompt | Inhibits the following prompts:
|
| NoSendKeys | WFC sends a dummy Control key after opening a segment on Ms-Word 2003 because of a VBA bug. Use this command to prevent this behaviour, if you have no problem opening segments with Word 2003. The most common symptom of the problem is that the first character you type remains blank - but only with an unpatched Word 2003. |
| NoWildCardsInPlacedTerms=*|?# | Lists the wildcards that should not be included when WFC places a glossary entry in the translation using AutoSuggest, or Ctrl+Alt+Down, or propagation. |
| OptionalTags example: OptionalTags= , <br> | Enter a list of tags, separated with commas, after the equal sign. These tags are ignored when WFC performs QA to verify that tags are identical in source and target. See the section on tagged documents for more information. |
| PlaceableCapitals | Forces WFC to consider words with a first capital letter as placeables. This command is only used with German, where the default rule is inhibited. |
| PlaceableGlossaryTrigger=1 | Sets the trigger level for AutoSuggest to suggest a terminology placeable to 1 (it is 2 by default). |
| PlaceablePlusSpace | Forces WFC to make sure there is a trailing space after a placed placeable. |
| PlaceablePlusSpaces | Forces WFC to make sure there is a space before and after a placed placeable. |
| PlaceableNone | Forbids WFC from considering any source term a placeable. Use with caution. |
| Propagate1 | When using CopySource, all recognized terminology (if terminology recognition is turned on) in the target segment is replaced with its translation. This command is also active with the "Translate" tool, but only for unknown segments which are replaced with the source segment using the CopySource function. This command is often associated with CopySourceWhenNoMatch. Important note: if propagation must be active during the pretranslation of documents (using WFC's Translate tool), see the command "ToolsTranslateWithTR" further below. |
| Propagate2 Propagate3 | Same as above, using glossary #2, or #3. The three commands can be used together. |
| PropagateAndHighlight | When propagation is done, propagated terms in the target segment are highlighted. |
| PropagateInReverse | Propagates terms in reverse order. This is for language pairs that have a predominantly reverse syntax order. |
| PropagateMethod=[],many,add | Determines the method for the propagation of recognized terms.
The first two characters (here, [], but <>, (), {} can be used) specify the characters that are added around propagated terms. The many switch determines whether all multiple glossary entries are propagated, in the glossary has multiple entries sharing the same source term The add switch adds propagated terms next to the source term (rather than replacing it). (i.e., one given source term is repeated, with different target terms). |
| ReportFolder="C:\MyFolder" | This commands tells WFC in which folder the various reports (Cleanup, Analyse, Translate, etc.) should be saved. If CleanUp, Analyse, Translate fail, make sure this setting points to a valid folder. |
| ReportMany | Normally, all reports (for the Cleanup, Analyse, Translate functions) have the same name, and new reports overwrite previous ones. This command instructs WFC to add a time stamp in the report's name, so that they all have unique names. |
| ReportsShowIni | This command adds the current INI file to all tools reports. |
| ReportWithTabs | This command instructs WFC to separate elements of the report with tabulators rather than spaces, so that they can be opened as Excel worksheets. |
| SegmentAll | Normally, WFC does not segment isolated numbers, or other pieces of text that do not contain any alphabetical letter. This command forces WFC to segment everything. |
| ShowMemoryIf<100 | Will display the contents of the TM above the currently opened segment if the match rate (the match precentage) verifies the value range (here it is "<100"). You could use ">80" or "<99" as well: the operator can be < or > and the value can be any number. |
| ShrinkInternalTags | Shrinks internal tags to a short, numbered tag system to shorten segments with long tags and make them more legible. This is done as a visual aid; actual tags are actually preserved. |
| SkipSegment>99 SkipSegment<80 | When manually translating an already segmented, bilingual document (using Alt+Enter), all segments that have a match rate higher than 99 (or less than 80 in the example) will be skipped. Other values can be specified, for example, SkipSegment>95. |
| ToolsTranslateSkipUnknown | Skips (does not segment) unknown segments when WFC's Tools/Translate tool is being used. |
| UpdateWithQuickClean | Before a Quick-clean operation, you will be asked if you just want to update your TM, without cleaning-up. If you say no, you can go on and proceed with Quick-clean anyway, so the regular use of Quick-clean is not affected. |
| WaitForMT=X | Where X is, for example, 5. Instructs WFC to pause X seconds while a segment is being machine-translated using a Ms-Word-base MT engine (not a remote MT engine). |
Wordfast Classic wordfast.ini en-US>fr-FR F1:Help
Dictation support Command prompt:
Expand segment=Expand
Shrink segment=Shrink
Copy source=Source
Delete Target=Delete
End Translation=Stop
Key Enter=#
PowerPointRemote=0
Note: Wordfast Classic does not generate dictation: that is done by third-party software.
This feature is only used to recognize WFC commands in the flow of speech.
It is only active when a segment is opened.
When a command is recognized, WFC removes it from the dictated text, then executes it.
If you use Dictation (aka VR for Voice Recognition) to dictate your translation, WFC can recognize a set of Wordfast-specific commands.
During dictation, use a command prompt followed by the command. The command prompt + command sequence lets WFC distinguish commands from actual text.
The example above works with English as target language, using the integrated "Dictate" feature introduced in Ms-Word in 2019.
Other VR packages and other command prompts can be used.
In this example, Stop is the command prompt.
To run a command during dictation, say 🔊 Stop followed by the command.
Stop was chosen because it is a one-syllable word made of three consonants and one vowel,
which is easily recognized by the VR software. Other prompts can be used.
For example, if you finished dictating the target segment, and you want to move to the next segment,
say
🔊 Stop Next.
To insert an AutoSuggest-ed item, use the item's number:
🔊 Stop 1 or 🔊 Stop One
places the first AutoSuggested item. This is the same as using Up/Down to select an item, then pressing Enter.
The F5 function key runs the "Start Session / Next Segment" command.
It can be typed on the keyboard, or sent by a remote control device, see below.
When dictation support is enabled, WFC uses predictive typing to guess what the most likely AutoSuggest is coming next if you mark a short pause.
This complex predictive mechanism considerably helps in source segments containing placeables that are difficult to dictate,
such as acronyms, uncommon proper names, figures and parameters, etc.
If you do not have any Machine Translation set up, WFC silently runs its own free MT source to drive predictive AutoSuggest.
That can be defeated by checking "No MT" in case you, or your client, forbids MT.
Note that in this case, MT does not propose translated segments: MT only drives a smart AutoSuggest feature.
You remain the sole translator aboard.
I illustrate this in my YouTube channel:
Dictating in Wordfast Classic
PowerPoint Remote Mode
I use a PPT remote when a translation job is dictation-friendly.
The benefits are:
| Remote button (PowerPoint remote) |
Key stroke (any device) | Action 1 | Action 2 |
| Next Slide | PageDown | If AutoSuggest is opened: Move one AutoSuggest item down. | If AutoSuggest is closed: Next Segment, but only if target is > 1/2 source length, cursor after . ? ! |
| Previous Slide | PageUp | If AutoSuggest is opened: Place the selected AS item. | If AutoSuggest is closed: Open the scratchpad. |
| Start Presentation | F5 | If a segment is opened: Move to next segment. | If no segment is opened: Start translation. |
All PPT remotes have at least the Next/Previous slide buttons.
Just make sure those buttons are associated with PageUp and PageDown.
Cancel (Escape) and F5 (Start Presentation) are found only on some remotes.
DIY for power users using a PPT remote with more buttons:
WFC macros start with "Wf", and are listed if you press Alt+F8 in Ms-Word.
You can associate PPT remote keys ("shortcuts") to any WFC macro, or macros of your own.
No MT This option prevents WFC from querying MT from a free web-based MT source offered by Wordfast in case you have no other MT set up and running. This allows translators who are on a strict no-internet policy to run a locally installed VR software with WFC. Note that the absence of MT reduces predictive typing.
Every translation trade fair has carefully crafted VR demonstrations that garner applause. Back at home, the disappointment matches the enthusiasm. That has been my experience ever since the late nineties and believe me, I paid for, installed, trained, and tested quite a few VR packages.
So, forgive my mundane consideration: I only care for the productivity gain.
The techno-religious approach to dictation is trying to get 100% reliable and faultless speech recognition at all times.
My profane approach is to tolerate some degree of "noise" (typos or poorly recognized text), as those will be corrected
during the inevitable proofreading/revision stages.
The reality of translation is that some documents, or segments, lend themselves well to dictation, some not.
VR has improved in recent years. On a VR-friendly translation project, with recent VR tech, even with correcting dictation typos, I see a good productivity gain. Granted, there is a learning curve, but it's much shorter than a decade ago. Refer to you VR package guidelines. To save you time, here is a general-purpose digest:
VR can relieve us from the dumb mechanical aspect of translation: the keyboard. We can then focus on our linguistic expertise.
WFC's way of counting words is slightly different from Ms-Word's statistics (Tools/Wordcount or Tools/Statistics). For example, in the following text:
L'argent de Louis-Philippe
Ms-Word counts 3 words, while WFC counts 5 words (a very similar word count is upheld by most translation tools). On average, WFC finds from 5 to 10% more words than Ms-Word, depending on the language. The difference is more striking with French, more modest with other languages. This way of counting is in keeping with most translation syndicates and unions in most countries using alphabetic languages.
Discuss the word count issue with your client before starting working on a project. That will avoid the silly bickering stemming from the client thinking "source words" and the translator assuming "target words".
On tagged documents (very rare nowadays), tags are counted as one word (regardless of their number of characters or words) and their number is also reported in the analysis final report. A tag is defined as any contiguous series of characters (spaces included) that have the tw4winInternal style.
Note that (as opposed to word count), tags are not included in the Wordfast Classic character count, because a tag is counted as one word; tags are included in the word count.
The WFC word/character count, as with all CAT tools, is based on what the tool considers to be translatable text. This can depend on the way you set up your tool. For example, adding the SegmentAll command in Pandora's Box forces WFC to consider any text as translatable, including isolated fields, figures, numbers, etc. which would otherwise be left out of the translation process. This point may cause a notable discrepancy with other translation tools.
The WFC word/character count can include, or exclude, headers and footers, and notes. Pay attention to word count when auditing a project, or producing an estimate. Ask yourself the question (if applicable) of whether the document contains bookmarks, and if it does, what the author/client wants to do of them; whether graphics or textboxes should be translated, whether headers and footers should be translated, whether the word count is based on source, or target (translated), text, how to count tags, if any (per piece? per word? per character? at what rate?), etc.
Latin-1 is a character set used for most West-European languages, including Scandinavian languages. It includes all English letters, plus a large number of accented letters. East-European languages like Polish, Czech, Hungarian, etc. use another character set known as CE or Latin-2 and do not fall in the Latin-1 group.
If you do not use Unicode, and your system is Windows NT4, Windows95, or Windows98, then the display of characters in the glossaries and in message boxes may perhaps not be possible, which is a minor annoyance.
I recommend using Windows 2000 (or a higher OS) and Ms-Word 2000 (or a higher version), or Word 2019 on a Mac, with Unicode translation memories, although older platforms may behave well.
The following discussion concerns the WFC-generated data (like translation memories and glossaries). It does not concern documents. Ms-Word documents always support Unicode, and do not lose encoding. If there are issues, those are font (rendering) issues, or material brought into Ms-Word by copy-pasting alien material.
Unicode translation memories and glossaries should be used for translation where one of the two languages (source or target) is CJK. All versions of WFC after the year 2007 use only Unicode TMs and glossaries, so that should not be a worry.
Use path names and file names with latin, non-accented (English) letters only for TMs, glossaries, INI files, and the Ms-Word Startup path (as displayed in Word/Options/Default file paths/Startup). Try to keep TM and glossary file names under 32 letters, using English non-accented letters, preferably without spaces. WFC may not support folder and file names with unicode characters. If WFC malfunctions, this could be due to the Ms-Word Startup path containing unicode characters. If this is the case, create a folder, for example C:\Startup, or MyMac:Startup and copy Wordfast.dot there. Start Ms-Word, use the Tools/Options (or Office button/Options or Preferences) > Default folders dialog box to change Ms-Word's Startup folder to the one you just created. Close and restart Ms-Word.
If given the choice of Unicode flavour when you save a TM or glossary, select the simple "Unicode" (this can be just Unicode, or UTF-16) setting, not a language-specific encoding.
If you use Ms-Word XP (Ms-Word 2002), note that a notorious Ms-Word 2002 glitch prevents it from saving documents as Unicode (unless you specifically added that feature at installation time). In this case, export the TM to unicode. To do so, start the TM/Glossary editor, click "Tools", and run the "Rewrite as Unicode" special filter. Another workaround is to open an existing Unicode document, delete all its contents, paste your data into it, save it then rename it directly on disk.
In WFC's main window, next to the translation memory path and name, you should see the (CJK) mention. This mention appears if the source language code begins with either ZH-, JA-, or KO-. This mention is essential for WFC to switch to a mode compatible with Chinese, Japanese, or Korean.
Notes:
For Japanese, Chinese, and Korean, make sure the full-width (double-width) punctuation (like ?!?) are visible in the WFC/Setup/General "End-of-segment punctuation"setting. They should be automatically added there when you create a translation memory with JA, KO, or ZH in the source language (for example, ja-JP, zh-CN, etc.). If you do not see the Japanese or Chinese full stop, question mark, exclamation mark, select them in a document. Copy them (Ctrl+C). Open WFC. In the WFC/Setup/General "End-of-segment punctuation"setting, press Enter to edit the value, then paste your punctuation before the existing punctuations there (I advise not to delete the existing, latin punctuation).
For Japanese and Chinese, check at least the "An ESP without a trailing space ends a segment" rule in WFC/Setup/Seg, so that end-of-sentence punctuations that are not followed by a space may still be recognised as ending a sentence. This too is normally done automatically by WFC when the TM is CJK.
To have all target segments receive a specific font (a font that can display CJK characters), use the WFC/Setup/General "Target font" setting to specify the target font. But this is not necessary if your platform automatically adapts fonts to languages.
To have both Concordance search and glossaries displayed using a specific font, go to WFC/Setup/Pandor'as box. Add the parameter TermFont="MyFont" with the required font instead of MyFont.
If you open a glossary or a translation memory with Ms-Word and cannot read the text: select all text then apply a font that can display your language (a specific font, or a generic Unicode font).
If you still cannot see text properly displayed, and all you see are question marks (????) then perhaps, at some stage, the file was saved as (rewritten) using a simple text or text-only or 8-bit ANSI format rather than Unicode. There is no way back. Make sure Unicode files remain Unicode at all times. This concerns the Text format used for translation memories and glossaries, not Ms-Word documents. Unicode is not relevant with the DOC file format.
If an Ms-Word document does not display your language properly, it's a font problem. Target segments must receive the proper font; see above for automatically applying a certain font to target segments.
This section deals with expert uses of WFC for tasks that require special attention. WFC does not guarantee operation because of its very nature as a mere Ms-Word complement. WFC is an add-on to a complex program (Ms-Word) that handles documents which, in the course of their lives, have been handled very differently by different people using different versions of Ms-Word (on PCs or Macs), through different formats (DOC, DOCX, RTF, HTML, etc.) and sometimes ill-conceived (with textboxes used instead of tables).
The special care section deals with tasks that are possible with WFC, but which need special attention in their execution, as well as a good knowledge of Ms-Word. Beginners should train themselves, or seek professional training, before engaging in projects outlined in the Special Care section. It is out of question for any translator to accept a "Special care" job wihout a prior understanding of the risks involved.
WFC is designed to translate the Word native "DOC" and "DOCX" formats. Tagged files are better translated with programs that were designed from the ground up to handle tagged files, like WF PRO.
WFC retains the capability to translate "tagged" files, but it should be noted that an Ms-Word tool cannot efficiently handle or protect tags. Translating tagged files with Ms-Word requires expertise, should things go wrong at any stage.
Some translation agencies, which are equipped with tagging software to prepare documents, may ask free-lance translators to work on tagged files. Agencies and free-lance translators should know that WFC is compatible with the most current tag formats, such as Trados and RWS Rainbow. Here is some advice for translating tagged documents. Please pay attention to the following advice, because tagged files that are not properly handled can cause serious problems.
Agencies that entrust tagged files to a translator for the first time should review the first translated file immediately after the translator has completed it, to make sure tags have been properly handled. If necessary, adjustments should be made before going any further into the project.
What follows is a crash course on handling tagged files with WFC and Ms-Word.
Internal tags
The red tags (usually with the tw4winInternal style) are internal and are mostly found within the text to be translated, in the translation. Those are sometimes called inline tags, because they appear inside a segment, as opposed to external tags.
| Example: | The <B>final</B> document. |
| translates as: | Le document <B>final</B>. |
In this example, <B> and </B> are tags that command the bold type in HTML. The translator has positioned the red tags at the right position in the translated sentence. The translated text does not have a tw4winInternal (neither a tw4winExternal) style (with a "Normal" or "Translatable" style). Only tags have a tag (tw4winInternal) style, red or grey. Styles are important, because tagging/untagging software relies on style, not font color, to differentiate tags from translated text.
! Be careful when typing. If you type regular text (for example, right after right after a <tag>), and notice that the text appears red, stop! Only tags must have the tw4winInternal style. Regular text should have another style, usually named "Normal", or "Translatable", whatever that is. In fact, the style of the regular text does not matter, as long as it is neither tw4winInternal nor tw4winExternal.
Note that to revert text from a tw4winInternal style (or any other style) to the default style, select the text and press Ctrl+Spacebar. A slower method involves the Style listbox, the mouse, etc. If you are not familiar with Ctrl+Spacebar, learn it right now: select some styled text, apply it and see how it works.
! Normally, internal tags must not be modified, edited or translated. Some tags can be added or omitted if the translation requires it. Otherwise, the golden rule is that all internal tags (usually enclosed between < and >) present in the source segment must be duplicated in the target segment, and positioned correctly.
To duplicate these internal tags, WFC provides a set of shortcuts. Ctrl+Alt+left/right will select the next/previous internal tag (in the source segment); Ctrl+Alt+down will duplicate ("bring down") the selected tag at the insertion point, in the target segment. You should get used to these shortcuts. For better speed, you can type < or / and AutoSuggest will pop up a list of available tags for quicker placement.
If you copy the source text into the target segment and translate by overwriting it, or if you edit an existing target segment, make sure the translated text does not have a tag (red or grey) style. If the cursor is immediately after a red (or grey) tag, whatever you type will also be red (or grey), and this causes problems later on. To avoid this, remember that if your cursor is immediately after a red tag, pressing Ctrl+Spacebar will restore the normal style at that point, and the text you type will not have a tag style. Ctrl+Spacebar is an Ms-Word shortcut.
In a regular tagged style, the only two important styles are tw4winInternal and tw4winExternal. Text outside tags can have any other style (styles named Normal, Translatable, etc.) or font attributes (bold, blue, whatever).
Here are examples of correct and incorrect translation units:
The <B>final</B> document is here. | ||
Le document <B>final est ici. | ✅ | This TU is correct. |
The <B>final</B> document is here. | ||
Le document <B>final</B> est ici. | ! | The target word "final" has an internal tag style. Select the red text ("final"), press Ctrl+Spacebar: job done, style corrected. |
The <B>final</B> document is here. | ||
Le document <B>final</B> est ici. | ! | The target segment's first tag has lost its internal (red) tag style. |
The <B>final</B> document is here. | ||
Le document <B> final est ici. | ! | The target segment's second tag is missing (it should be </B>). |
WFC has a Quality Assurance option called "Identical tags in source/target segments". I recommend turning this QA option on. To avoid having false alerts for tags that are actually optional, use Pandora Box' "OptionalTags" command in WFC/Setup/PB.
Most optional tags are tagged items (like the unbreakable space, quotes, ampersand etc) that look like & or <:hs> or etc. You may have them in the source segment but not in the target segment, or the reverse, according to the translation's needs. Thus, the following segment:
The R&D department is <B>ready</B>.
Le département "Recherche et Développement" est <B>prêt</B>.
is valid, even if there are three internal tags in the source segment and two in the target. The source segment's ampersand has not been re-used. There may be other exceptions where even non-optional tags must be added or omitted.
Long tags
WFC considers any contiguous text with an Internal style as a one tag. So for example
<p align=left font="Times New Roman" size="12"><strong><table align=center>
is considered one tag.
If this contiguous stretch of text actually contains more than one tag, and if these tags have to be handled separately, use the Ctrl+Alt+Up shortcut to make WFC treat this tag as separate placeables. The pairs of characters < and > as well as & and ; will be considered as tag beginning and tag ending.
External tags
External tags (tw4winExternal style) are kept out of the translation. Like internal tags, they must not be edited, deleted, translated etc.
! In case of doubt, stop and ask the client or the agency. Do not proceed if you are not sure you handle tags correctly. If you start working on a project with tags for the first time, submit your first translated file for review and approval before going any further.
Starting in 2019, Ms-Word is equipped with an excellent PDF conversion feature that solves a huge problem. Simply open a PDF in Ms-Word, and presto, you have an editable document, compatible with Wordfast Classic.
The PDF (Portable Document File) format was designed at an age when most systems lacked fonts, or were equipped with very different fonts. The PDF format contained the fonts it used, making it very portable.
The other selling point in PDF was its percevied "Read-only" nature, so legal professions made extensive use of PDF.
There is no reason to keep using PDF, since those two reasons are no longer valid.
The difficulty to alter PDF content has been a misery for translator for decades. It's good news that Ms-Word now opens PDF for edition. Unfortunately, some PDF documents (so-called "Dead PDFs") either lock their content, and/or only contain graphics (screenshots) of text, not actual, selectable text.
One way to solve this problem is to maintain a subscription at Wordfast Anywhere, which offers a stellar conversion tool for PDFs that contain scanned text (pictures of text).
Note that no tool will let you translate a PDF "from within", and deliver a visually correct translated PDF at the push of a button. PDFs must be converted to another format, and even that process is hazardous. Ms-Word's PDF conversion feature, as of 2019, is pretty good, compared to other solutions.
When a source segment contains a footnote reference (a number that looks like this: 1 and which, if double-clicked, opens the corresponding footnote), start translating the target segment as usual. At the point where the footnote reference should appear in the translated text, use Ctrl+Alt+left/right to select the footnote reference (it should be boxed in red), then transfer it into the target segment using Ctrl+Alt+Down. If these shortcuts are not available, you can use the corresponding icons (Next/Previous/Copy Placeable) in the WFC toolbar.
You can also manually select the footnote reference, cut it (not copy it) and paste it into the target segment. The important point is to actually cut (not copy) then paste the footnote reference (move the footnote reference), otherwise you would duplicate notes.
When the document's translation is over, double-click any footnote reference to open the footnote pane (the current window will split and the bottom half will show footnotes) to translate the actual footnotes. Simply put your cursor in a footnote and start translating as usual with WFC. You can translate foonotes immediately after a segment, by closing the segment then opening the footnote pane and translating the footnote. But I recommend translating all footnotes in a separate translation session when the document's translation is over.
After you transfer a footnote reference, WFC will replace the source segment's original footnote reference with a "dummy" footnote reference number, so the revisor can know where the original footnote reference position was.
Note that when there are multiple footnotes references in the same segment, they will appear wrongly numbered after you transfer the first footnote reference. The correct numbering will be restored when you transfer the segment's last footnote reference.
In case of mistake, use Ms-Word's undo function immediately after pasting a footnote..
An Ms-Word document can contain fields or objects like hypertext links, buttons, graphics etc. Normally, fields (to the exception of hyperlinks) should not be translated, unless specifically required by your client, like index fields, for example. Fields should be copy-pasted from the source segment into the target segment. Note that the F9 function key can toggle the two views of fields: either the result of the field (a field is a programmatic instruction processed by Ms-Word, usually resulting in some displayed text - the result), or field codes, which look like { DATECREATION \* FUSIONFORMAT }.
When fields are present in the source text and no proposition comes from the TM, you may consider using WFC's Copy source icon ⮫ to copy the source segment into the target segment, and translate by overwriting it, leaving fields or objects unchanged. Otherwise, individual fields and objects should be carefully copy-pasted into the target segment's translation, at the appropriate location.
Read the general introduction to fields (above), if this is not yet done.
Fields where the result (not the code) must be translated.
Hyperlinks are a good example. These fields should be manually copied from source to target, then manually translated - toggle the field's view with Alt+F9 as necessary, so you can edit the translatable element (the result). Another approach is to right-click the hyperlink, then select "Edit" and translate the field's displayed text.
With Ms-Word 2000 or higher, right-click the field, click "Hyperlink", then "Edit hyperlink". The translatable item is at the very top of the "Edit hyperlink" dialog box.
Fields where part of the code must be translated.
The code for most fields cannot, and should not, be translated. There are a few exceptions to this rule, like index fields ("EX", "XE"). Such fields have a translatable item, contained between quotes as in the following example:
{XE "Translatable text:Page 4 Figure 5" \b \r }
Make sure Ms-Word's View options (Tools/Options/View or the Alt+F9 shortcut) are set to display field codes and hidden text.
When you open a segment with translatable fields (and the TM does not bring any match), you can use the Previous/Next Placeable utility (Ctrl+Alt+Left/Right shortcuts or the icons: 🡄 🡆 to select the field in the source segment, then copy it down (Ctrl+Alt+Down 🡇 at the proper position in the target segment. At that moment, WFC will display a text input dialog box containing the translatable part of the field and will wait for the translation (if a match is found in the TM, it will be proposed).
Another way is to use the CopySource icon ⮫ or shortcut (Alt+Insert). When WFC copies a source segment with translatable fields, it will take you to each translatable field and prompt you for translation.
It is also possible to directly edit the editable part of the field in the document, if the field codes are made visible (Alt+F9). This is recommended if the above method fails for some reason.
See the glossary of terms if you are not sure what a bookmark is.
Handling bookmarks, or not handling bookmarks, is a question to be discussed with the client. In many projects, the author or the client may not need bookmarks to be positioned in the translated text. This is simply due to the fact that in many cases, bookmarks are part of a complex, carefully engineered scenario, and the document's owner may rather wish an engineer, or a technician, to re-position bookmarks on the translated document, then test the entire document again. In this situation (the translator not being required to position bookmarks in the translated document), simply click "No" if WFC prompts you to have bookmarks prepared for translation.
Your client should inform you of the presence of bookmarks and give you instructions (transfer them or ignore them), since it is the client, or the author, who has introduced the bookmarks in the first place. However, your client may not be the author of the document(s), and the client may not even know what a bookmark is. In this last case, use tact and wisdom to make sure what should be done. The bottom line is: do not transfer bookmarks - a complex task at times - unless your client asks you to do so; but if you have to handle bookmarks, carefully weigh and estimate the extra workload. A bookmark, at the very least, should be billed as ten words, although it usually takes longer to correctly position the two ends of a bookmark than to translate two words.
Normally, bookmarks found in the source text should be transferred into the target text, over the corresponding span of translated text.
One important point is, since two bookmarks cannot have the same name in the same document, bookmarks must be transferred (moved), not copied, into the target text. In other words, you cannot duplicate or copy bookmarks as you would, for example, duplicate or copy fields.
Before starting a translation session over a document that contains bookmarks, WFC will warn of the presence of bookmarks and propose to mark them using conspicuous red markers positioned at the beginning and end of the bookmark, like this: [ and ]. If a bookmark has a null length, you would see []. Answer "Yes" to have bookmarks thus marked.
WFC will prompt you only once (per document) for marking bookmarks. If you answer "No", then WFC will not prompt you anymore for marking bookmarks on the current dcoument unless you open a translation session with the cursor at the very top of the document. If you answered "No" by mistake, or if you want to mark bookmarks at a later stage, use the WFC menu, select the Miscellaneous submenu and run "Unlink". Once the document has been "unlinked", WFC will prompt you again for marking bookmarks if you start a translation session.
During translation, if a source segment contains red markers, all you need to do is use the Next/Previous/Copy Placeable icons 🡄 🡆 or shortcuts (Ctrl+Alt+Left/right/down) to select or box the red bookmark markers (they always come in pairs, opening and closing), then transfer the red marker(s) at the appropriate location in the target segment using Ctrl+Alt+down 🡇 .
When cleaning up a document, WFC will remove the source segments as usual then replace the red markers in the target segments with the appropriate bookmarks.
WFC's Quick-clean function will propose an option for processing (restoring) bookmarks without cleaning up the document. This is useful for translators who are required by the client to send back "uncleaned" or "bilingual" documents (for example, because the client wants to clean up the documents with a different tool, not with WFC). In this case, the document is not cleaned up, but all bookmark markers are removed, bookmarks are correctly assigned to the target text.
Pay attention to the bookmark question before beginning a project, because handling bookmarks takes time; if the problem is overlooked, reconstructing bookmarks manually on a translated document can take a long time.
The WFC Translate tool's default behaviour is to mark bookmarks. If you want to prevent this, add TranslateIgnoreBookmarks in Pandora's box.
Bookmarks can be found in many different types of documents, and they are put to many different uses. Documents that contain hyperlinks, indexes, or Tables of Contents usually make considerable use of bookmarks.
(PC only) WFC can be linked to virtually any external dictionary application, such as the Collins™ On-line, Harrap's™ Shorter, Merriam Webster's™, Microsoft Encarta™, any web-based dictionary or database, Trados Multiterm™ etc, using the Select dictionary button of the Terminology/Reference tab.
The access keystroke (Keys button) defines the keystrokes used for accessing an external dictionary, where some fields are replaced with values as in the following table:
To set up the "Keys" parameter, start your dictionary application, then note the sequence of keystrokes necessary to perform a word search. Once this is done, click the Keys button and enter the caption of the dictionary application window, followed by a semi-colon, followed by the keys you noted. For example,
Harraps;{pause}{F3}{Escape}%e{SearchWord}{Enter}
will instruct WFC to look for an application whose window name begins with Harraps, activate it, pause for 200 milliseconds, then type an F3 key, followed by an Escape Key, then Alt+E, then the searched-for word, then an Enter key.
All typable keys are simply entered as they are, in lowercase. Function keys and other special keys are entered as follows:
Once the dictionary has been setup, close WFC. Position the cursor on a word, or select an expression, and click the Dictionary icon  (or press Ctrl+Alt+D. For the dictionary #2, use the Ctrl+Alt+F shortcut). WFC will launch the dictionary application (or activate the relevant window if the application is already running) and execute the sequence of keystrokes you defined.
(or press Ctrl+Alt+D. For the dictionary #2, use the Ctrl+Alt+F shortcut). WFC will launch the dictionary application (or activate the relevant window if the application is already running) and execute the sequence of keystrokes you defined.
Disclaimer: this feature converts from US Customary Units to Metric, and back. For other measures (such as British Units, or the older Imperial Units), the set of signatures must be modified. The default set of conversion signatures is in an editable resource text file named WFC9.en.ui, located in the same folder as wordfast.dot. The list of conversions is located at the end of the file, for major languages.
Wordfast Classic's AutoSuggest feature is equipped with an automatic conversion utility as of version 6.28, January 2016.
The mission statement for the WFC converter is:
| A 300-pound gorilla escaped the zoo. |
| Un gorille de 3 | |
|
In the above EN to FR example, typing the number 3 pops up a suggestion for a converted measure. In a non-scientific translation, rounded measures like 125 or 150 can be preferred to the surgically exact 135,9 kilogrammes.
WFC's converter should spot and convert most abbreviated/full measurements, singular or plural, between US Customary Units and Metric. The source measurement should follow a number, only separated from the number with either a space, or a non-breaking space, or a minus sign (dash, or hyphen). In other words, with the example above, the following formats are recognized:
300 pound, 300 pounds, 300-pound, 300 lb, 300 lb., 300-lb., 300-lb, 300 lbs...
However, the following forms may not be recognized:
300 US pounds, 300-plus pounds, 300 more pounds...
because there is an unrecognized word between the number and the unit.
WFC attempts to convert, then suggest, financial formats following the most likely conversion rule.
Note that the Setup > General dialog box in WFC lets you enter the values for the target language thousand and decimal separators, as well as abbreviated dates. Those are ,.- (comma, dot, dash) for EN-US as target language, and will often be .,/ for European languages, with possible variations, such as French, which uses non-breaking space, comma, slash, noted as ~,/ (the tilde character ~ means the non-breaking space).
| Today's lottery is worth $400,000.00! |
| La loterie d'aujourd'hui vaut 4 | |
|
| The meeting is scheduled for 2016/12/31. |
| La réunion est prévue pour le 2 | |
|
Note that WFC proposes three formats here: the original one, and two that were reversed to fit non-English formats, using the two major separators.
The set of signatures is automatically generated by WFC based on your language setup.
This set of signatures is provisionally generated for a few languages such as CS, DA, DE, EN, ES, FI, FR, IT, JA, HU, NL, NO, PL, PT, RU, SV, ZH. The set of signatures assumes that EN-US is either the source or target language. Other languages may be submitted by the community and will be available by download.
Customization of conversions
The set of signatures is in the WFC7.en.ui file and can be edited as a text file. The file is located in the same folder as wordfast.dot, and is named wordfast.en.txt, or wordfast.local.txt. For a language pair like EN to FR (English to French) , conversions are located at the end of the file, listed for en-xx and fr-xxx as follows:
en-xx-cnv="=*2.54,acre=*0.4046,acre=*4046,acres=*0.4046,acres=*4046,cu. feet=*0.283,cu. foot=*0.283,cu. ft.=*0.283,cu. in.=*16.38,cu. mile=*4.1618,cu. miles=*4.1618,cu. yards=*0.7645,cubic feet=*0.283,cubic foot=*0.283, (...)
fr-xx-cnv=cm,mètre carré,hectare,mètres carrés,hectares,mètres cubes,mètre cube,m3, (...)
Every EN measurement in the en-xx-cnv setting has a name (like "acre", or "cubic yard"), followed by a conversion formula, where * means multiplication, and / means division. Values are separated by commas.
For example,
acre=*0.4046
means that, if a number is followed by acres, like perhaps "120 acres" in the source sentence, then WFC will calculate 120 x 0.4046, and suggest 48.552 hectares. Values rounded to the nearest 5% and 10% are also proposed (like 50 hectares in that example).
In the signature file, the same measures may appear under different forms, like various abbreviations (pound; lb; lb.), or singular and plural forms (pound; pounds). This redundancy is meant to enhance the chances of spotting the pattern in the source text. Wildcards are not used, this is why singular and plural forms of the same measures are used in the signature file. Note the unorthodox English lbs abbreviation in the supplied signature set. They are necessary because of the poor quality of some technical documents. You may even enter a custom and horrific lb's (OMG!) if the English you are translating is of appalling quality. CAT tools belong to the realm of what's practical rather than what's ideal -- possible versus perfect.
Note: the very first measurement in the English (en-xx-cnv) setting is a straight double quote like " - this is because " is sometimes used in place of "inch".
Wordfast Classic can connect over the web/intranet to Translation Memories and Glossaries hosted by Wordfast Server (WFS).
Benefits:
Caveats:
You are welcomed to download Wordfast Server and experiment for yourself. Please note that the Wordfast hotline cannot offer support for a free version of Wordfast Server. You must be comfortable with setting up over-the-web services, and have a good knowledge of Wordfast Classic's TMs and Glossaries. The Wordfast Server manual offers good guidance on setting up Wordfast Classic with Wordfast Server.
Introduction
WFC translation memories and glossaries share the same format: tab-delimited text. This format is perhaps the most simple database format you can find - most other translation tools use proprietary formats that render direct data maintenance difficult (illustrating the concept of "captive market"). WFC remains committed to user-friendly formats, and to the competition's sustained astonishment, performance is not hampered at all by WFC using open formats.
To make a long story short, you can consider that both your TMs and glossaries are regular Ms-Word documents and use Ms-Word to maintain them: edit, proof-read, cut, paste, merge, etc. Countless other popular software can be used to maintain WFC data, and should any ad-hoc tool be developed for specific purposes, the openness of the WFC format is a welcome simplification for engineers. If the TM is too large for Excel™, then Ms-Access™, Ms-Word, FileMakerPro™, dBase™, FoxPro™, Paradox™ etc. will open it anyway. Even the diminutive Notepad™, JustWrite™, WordPad™, SideKick™, XyWrite™... can open small to medium TMs.
The TM/Glossary editor
Click the "TM/Glossary editor" icon in WFC's main toolbar, or the last icon in any of the glossary toolbars to start the TM/Glossary editor. Outside a translation session, glossary toolbars can be opened using the Ctrl+Alt+Right shortcut (and closed using the Ctrl+Alt+Left shortcut). During a translation session, the Ctrl+Alt+G shortcut pressed on a word or selection will open the glossary toolbar(s) of the glossary(ies) where the term was found. Glossary toolbars open only on glossaries that were specified in WFC/Terminology.
WFC's TM/Glossary editor is intended to make maintenance easy and intuitive, and offers practically identical methods for TMs and glossaries. Once the editor is opened, you can scroll up/down the data, edit/delete/add entries.
Note: cutting (deleting) a single line (or entry, or TU) is a soft operation, meaning it can be reversed or undone (press Delete twice on an entry to see the toggling effect). When an entry is cut (or soft-deleted), it appears as a blank line, but when it is selected, the source and target data appears in the editor's bottom blue/green display. Ctrl+Delete will permanently erase cut entries by "packing", i.e. rewriting, the entire TM or glossary.
TM Tools contains special filters are meant to perform operations that would be difficult or impossible to perform with just filtering and sorting. These operations are:
Mark redundant entries
(there are various types of definition for a redundant entry, depending on whether you use a TM or a glossary). This feature marks entries that are considered duplicates. Once the marking is done, you can review them, then delete them all by using the Cut shortcut (Ctrl+X) followed by a hard-delete command (Ctrl+Delete). Of course, with a TM, such entries are grouped if the TM is sorted on the source segment.
Reverse source and target
This will rewrite the current file and reverse source and target fields.
Export to Unicode
Exports the current file to a unicode format.
Export to TMX (TM only)
Exports the current file to the TMX format. The TM is not overwritten - a new file is created, and it has a .tmx extension.
Export to TBX (Glossaries only)
Exports the current file to the TBX format. The glossary is not overwritten - a new file is created, and it has a .tbx extension. The TBX format is a popular glossary exchange format (TBX stands for Term Base eXchange) among translation tools.
Remove tags
This special filter removes tags from a TM. This is recommended after finishing a project with tagged files. The leverage of TUs with tags is precious within the scope of a particular project. Tagged leveraged outside a project is an extreme rarity. This is why it is recommended to remove tags from a TM that will be used on different translation projects. Tags bloat TMs to a ridiculous extent.
Export as segment document
This filter will create a segmented document in Ms-Word that contains all Translation Units (TUs) in the TM.
Repair and compact TM
This maintenance will rewrite the entire TM, removing lines marked for deletion, removing empty lines. It will re-create the index. This filter can be run if the TM does not perform well, or before storing or archiving a TM.
Mark suspicious TUs
This powerful feature can help to clean up a TM by marking TUs that statistically look suspicious for various reasons.
After the filter is executed, TUs that look suspicious are simply marked (checked, or selected).
Various methods are used to detect suspicious TUs:
All of the above are rules that suffer exceptions. WFC is a statistical machine, and does not "understand" text. WFC only helps spot TUs that look suspicious to a machine. Stopwords are kept for about 30 languages only, and are found at the end of the WFC9.en.ui text file. You can add your own list of stopwords there if your language is not listed. Modifying the existing list of stopwords can be done, although that may not help much. Adding many stopwords to the more or less 100 existing ones will not change much to the results. Suspicious TUs are marked after the tool is run. You can review and delete them as needed. Note that Ctrl+X deletes all marked entries in one time.
Rewrite Entries with a Mask
This powerful feature is used to replace a particular field, or many fields, with some given value, or erase the content of the fields, in all visible entries. Visible entries are those that are displayed in the editor. If a filter is set, only some entries are visible.
You are first presented with an empty entry (a mask). You can:
All fields that are left blank (or which do not begin with = followed by at least one character) in the mask will remain untouched in the file.
The following mask would replace all User fields with "FOO", and erase Attribute fields 1, 2, 3, 4 in the entire TM:
Practical example: "I have that older, bulky TM that combines TUs from various translators. I want these entries grouped by user (translator) name. I want to delete all entries that have a usage counter of less than 2, and that are older than August 31, 2004. Then I want to review them one by one and perhaps have some entries not marked for deletion if I think they're useful after all. Only then will I erase all marked entries that remain".
Note that all operations except #7 can be undone.
Extract an auxiliary TM
This feature uses the current TM or BTM to generate auxiliary TUs,
and send them to a separate TM, the auxiliary TM.
That TM can then be added to the current TM, or set as Background TM to temporarily boost leverage for the current TM.
When is this useful?
Ms-Word documents that are created by converting PDF or internet content often suffer from serious issues.
Translators on tight deadlines may not have the time to fix such badly formatted documents.
Note that WFC offers a tool to alleviate the problem by attempting to reconstruct broken paragraphs
in documents. This function is in the Tools > Misc section of the main WFC setup dialog.
Badly formatted source documents may generate the following problems in a TM:
It is understood that ¶
this agreement was passed ¶
between the parties.¶
Every line may have been segmented separately. As a result, the TM has TUs containing incomplete chunks of text. This is where this feature comes handy: WFC will parse the TM and join consecutive TUs that appear to be incomplete. Note: the TUs thus extracted are sent to another TM (the original TM remains untouched). That Auxiliary TM should be considered a "dirty" TM. Its sole purpose, when used in conjunction with the main TM, is to boost TU leverage on a given job. If the auxiliary TM is set up as background (read-only) TM, which is recommended, any match it proposes, if validated by the translator is written into the main TM. The auxiliary TM should be kept separate from the main TM, and discarded after a while.
The "Extract Auxiliary TM" tool reads all TUs in the order they are in the TM. The conditions for two or more TUs to be joined are:
No more than 4 TUs in sequence are joined. Example: in the TM, WFC reads those three TUs:
- The time stamp difference between the two TUs is less than 5 minutes;
- the user ID is the same;
- the first ("mother") TU does not end with a full stop, or exclamation mark, or question mark;
- the "child" (next) TU does not start with a capital letter - unless both TUs are fully capitalized.
20200420~134323 ↦ YAC ↦ 0 ↦ en ↦ It is understood that ↦ fr ↦ Il est entendu que
20200420~134413 ↦ YAC ↦ 0 ↦ en ↦ this agreement was passed ↦ fr ↦ ce contrat a été conclu
20200420~134443 ↦ YAC ↦ 0 ↦ en ↦ between the parties. ↦ fr ↦ entre les parties.
The above three TUs fill the conditions listed above. WFC assumes they belong together, as a result, they are joined in sequence, and written as two new TUs in the artificially created TUs, some of which may not be linguistically correct. Those incorrect TUs will rarely, bring up "matches". Here is how that auxiliary TM would look like:
20200420~134323 ↦ AUX! ↦ 0 ↦ en ↦ It is understood that this agreement was passed ↦ fr ↦ Il est entendu que ce contrat a été conclu
20200420~134413 ↦ AUX! ↦ 0 ↦ en ↦ It is understood that this agreement was passed between the parties. ↦ fr ↦ Il est entendu que ce contrat a été conclu entre les parties.
The provisions are set on Clause III. Our counsel in New York has received a copy.
Even if the TU above is correct, we may run, in another job, into two distinct sentences such as:
The provisions are set on Clause III.
Our counsel in New York has received a copy.
Having those sub-segments in the TM would be nice. WFC will attempt to extract such segments where it appears possible to break them down into two sub-segments. Once again, the method may produce incorrect sub-segments, however, those have little to no chance to be served.
7.1 The provisions are detailed in the preamble. 100/08 ¶
7.2 Please note that they are legally binding. 100/09¶
7.3 No other provisions should be considered. 100/10¶
7.4 The court does not accept other evidence. 100/11 ¶
WFC will extract those TUs, cleaned and free from wrapping parasite characters (figures or bullets). That will give a better chance for those TUs to be leveraged in other jobs. Here is an example of the auxiliary TU thus generated for the first line:
20200223~130320 ↦ AUX! ↦ 0 ↦ en ↦ The provisions are detailed in the preamble. ↦ fr ↦ Les dispositions sont détaillées dans le préambule.
Filtering means you define a condition with a Field Condition Argument format.
For example:
SourceText & "MyText
where & means "contains", or
Counter = 0
See more examples in the Filter or Sort dialog box' Help.
When Argument is made of text, it must be enclosed in straight quotes like this: "MyText".
The effect of a filter is that only the entries that conform to the filter's condition(s) will be made visible in the glossary editor. When a filter has been set, using the Mark methods (mark, unmark, copy, paste, cut) will operate only on visible entries.
In the Data Editor, use the F8 shortcut to cancel a filter.
Sort files only if you need. Sorting can take some time, because the entire file is actually (physically) sorted, not just the display of the file. Sort when necessary. WFC adds the convenience of being able to sort source or target text on the number of words or characters in segments. This can be useful for terminology extraction.
This is a standard Find-replace operation. The operation is done on one specific field at a time. Ctrl+H gives you quick access to this feature when browsing a file.
With this feature, you can replace a word like "Smith" into "Jones" in the TM's target segments. Be careful that find-replace operations do not produce unwanted results.
Example: Changing language codes in your TM
Suppose your source language code is EN and you want to change it into EN-US: Select "SourceLanguageCode" in the list of fields, enter EN as search, enter EN-US as replacement. Click OK.
TMs and glossaries must be created for one language pair only. I also advise keeping separate TMs for different subject (domain) and client, and having them in dedicated folders so that keeping track of them, and especially backing them up, remains easy.
TMs keep growing all the time. Most of TUs are very unkikely to be re-used, while a minority of them will. Since WFC keeps track of how many times a TU is re-used in the usage counter field, it is advised, when a TM reaches a large size (over 100,000 TUs), or when finishing a large translation project, to perform a compression by eliminating all TUs that have never been re-used. As a result, the TM's size will be considerably reduced, while its overall efficiency will be preserved. To do so:
Creating a startup TM. Create one single, large TM by combining all the TMs you have. Delete all TUs that have a usage counter of less than 3. To compress further, you can visually review the TM and delete TUs that are unlikely to pop up again. To do so, sort the TM on "SourceWords", go to the end of it and review the TUs that are the longest, where there are likely "ghost" candidates, longish TUs that are unikely to show up again. Delete them. This TM can then be used as a primer - if you need to create a new, empty TM, better use a copy of that TM instead, because it contains a "Top 50" or perhaps a "Top 1000" of your previous work. It's like priming a pump with a cup of water.
A WFC TM may contain TUs where the first figure of the date (normally "2", but it can be "1" for TMs created in the previous millenium) is replaced with "x", and which, as a consequence, appear to be "cut" in the editor. This is because, in the course of a translation session, the TU was proposed as 100% match on a green background, but the target segment was edited, so WFC has deleted the original version of the TU in the TM and has re-written the TU's edited version at the end of the TM. This is normal. Do not "resurrect" or un-delete such TUs: their correct version appears further down in the TM. During translation sessions, WFC is blind to TUs that are marked "x". As a rule of thumb, perform a "Reorganisation" of the TM before working on it. This is done with the WFC > Translation memory > TM "Reorganise" button and it erases all TUs that were marked as "Deleted" with an "x" mark in the course of previous translation sessions.
Sharing TMs with other WFC users, or with other CAT tools.
Sharing TMs with other CAT tools: open the TM with the TM/Glossary editor, click Tools, apply the "Export TM as TMX" special filter. The TM will be re-written as TMX and the file's extension will be changed to .tmx.
The largest possible unit of segmentation with WFC, as with most translation tools, is the paragraph. Paragraphs end with a paragraph mark (ANSI 13 with or without page feed ANSI 10), page feed (ANSI 12), end of cell (ANSI 7). Not that the manual line feed (ANSI 11) does not end a paragraph. Nevertheless, WFC can be set up to consider the manual line feed as ending a segment: see the section on customizing ESPs, or the note further below.
WFC attempts to recognize individual segments within a paragraph by parsing the paragraph and looking for End of Segment Punctuations (ESPs). The default ESPs used by WFC are . : ! ? as well as the tabulator mark, noted ^t by WFC, and the manual line feed, noted ^l . Users can edit the list of ESPs to fine-tune segmentation, although that is not recommended, as it breaks their TM compatibility with most other TMs.
If all ESPs are deleted, WFC segments at the whole paragraph level. This is not recommended, as some paragraphs may exceed the acceptable segment limit of 8,000 characters (nearly two large pages!) imposed by WFC, although segments of that size are very rare. If a segment is larger than 8,000 characters, WFC ignores the extra characters, which can be segmented with the "ForceSegment" shortcut.
To remain compatible with most other tools, WFC does not consider the manual line feed (noted ^l ) as ending a segment. Users can add ^l to the user-defined list of ESPs in WFC to break segments when a manual line feed (ANSI code 11, decimal) is encountered, which is generally considered more logical. However, by default, WFC does not end a segment at a manual line feed.
Within a paragraph, WFC will consider that it has reached the end of a segment if:
Rules 2, 3, 4 can be disabled by the user in the WFC > Setup > Segments pane. With CJK languages, rule 2 is always disabled, and the "wide-character" equivalent punctuations are also used.
Rule concerning the beginning of a segment
If a segment begins with a series of numbers (or combination of numbers and full stops) followed by a full stop, WFC assumes that it's a numbering scheme, and skips the apparent numbering scheme. With the following text:
10. This is text
the segment will begin with "This is text", skipping the initial "10.". If the initial number is actually part of the segment, translators can press Alt+Delete (Unsegment), then select the entire sentence and press Shift+Alt+Down (ForceSegment). Translators can also set WFC to always override the number-skipping behaviour with the SegmentAll command in Pandora's Box.
Parts of text not considered as segments.
Isolated series/combinations of numbers, spaces, punctuation do not constitute a segment. For example,
100
100.89.67.90
100 (9078) // 67-56
will be skipped by WFC as being "numbers". But
100a
100.89.67.90Z
100 (9078) // 67-56P
will all be segmented, because at least one letter is present in each series of numbers/punctuations. The SegmentAll command in Pandora's Box will force WFC to segment isolated series of numbers/spaces/punctuation at all times.
Abbreviations
Users can specify a list of abbreviations in WFC > Setup > Segments. WFC will not end a segment if its last series of characters matches any of the abbreviations, case-sensitive. For example, if "Pr." is listed in the user-specified abbreviations, which is the case by default, the following sentence will be considered as making up a whole segment...
Here is Pr. Johnson.
... although "Pr." is followed by a full stop, a space, and a capital letter.
There are many translation-time shortcuts and options that let the translator fine-tune segments to expand them, shrink them, or force a selection of text to be considred a whole segment, regardless of rules. However, translators should remember to prefer default segmentation whenever possible, to remain compatible with other TMs.
A WFC translation memory is a tab-delimited text file. It's the simplest of all formats - it can be opened with text editors, like Notepad, or Unicode-compliant word processors, as well as with Excel. WFC TMs can be ANSI (8-bit) text, or the recommended Unicode UTF-16 (both little-endian and big-endian).
A Translation Memory (TM) is a set of lines of text. The very first line in a WFC TM is a header, and all other lines are Translation Units (TUs), sometimes called "entries". Lines (aka TUs) are sets of fields, a field being any text (even lack of text, which denotes an empty field) followed by a tabulator. In other words, the WFC TM format is Tab-delimited Text, which is arguably one of the oldest, most robust, open, easy to manipulate data format ever. In the header (the very first line in a TM), each field begins with a % (per cent) mark. This design ensures that, if the file is accidentally sorted, the header remains the first line.
Fields in a TU:
Here are the first two lines (the TM's header and first Translation Unit) of a TM.
Fields are separated with tabulators noted ↦ here below.
Lines are long, so they may wrap in your display - but there are only two lines:
%20041231~160445 ↦ %YAC, Yves A. Champollion ↦ %TU=00000000 ↦ %EN-US ↦ %WFC TM v5.0 ↦ %FR-FR ↦ %87412764 ↦ Domain ↦ Client
20041231~165410 ↦ YAC ↦ EN-US ↦ Red Riding Hood was walking in the woods. ↦ FR-FR ↦ Le Chaperon rouge se promenait dans les bois. ↦ EL PS
The header (first line in the TU) in the example above defines two attributes named Domain and Client. The first TU contains two attribute values: EL and PS. Either attribute names (unique per TM) or attribute values (multiple: one per TU) can be made of up to 64 characters (acronyms are used in the example above: EL for Electronics and PS for a client, however, longer descriptors can be used). Question/exclamation marks ( ! ? ) are forbidden in attributes names and values.
When parsing a TU, WFC defaults on the side of optimism in case the TU does not look correct or canonical. When non-critical fields are malformed:
If you need to archive a TM, or send it to a colleague, the only necessary file is the .TXT file. It is recommended to reorganise a TM before sending it to someone (using the WFC/Translation memory/TM/Reorganise button).
If a translation memory is lost, remember that (if you keep copies of your translated, segmented files) cleaning up the segmented files that produced the TM will recreate the corresponding TM with its translation units.
Fault detection (ignoring malformed TUs)
WFC considers that a TU is a bad one based on counting how many tabulators are in a line of text.
A line of text with less than 6 tabulators cannot form a valid TU.
Another fault-detection method used by WFC is that language codes should not be no longer than 5 characters.
When language codes of more than 5 characters are encountered during a TM reorganisation, it is an indicator that something is amiss with that particular TU, and it is assumed to be faulty.
WFC does not halt on faulty TUs, it ignores them, and moves to the next line.
This optimist behaviour with faulty data is similar to the way browsers handle HTML.
Remarks:
The date does not necessarily have a tilde (~) separating date and time. Any printable character can be used there, except a number. WFC uses the tilde (~), the equal (=) sign, and the star sign(*). The equal sign means the TU was "marked" (flagged) by WFC's data editor. This has no consequence on the TU's status: it remains fully valid. Although WFC always records the date and time when writing a TU, the date and time are optional and could be empty (or even made of an invalid date) in which case WFC would simply assume the current computer's date and time, or previous TU incremented by one second, if in a sequential loop. Dates and times are "local", taken from the local computer's clock.
If any optional field is left empty, its trailing tabulator should be present. For a TU to be valid, there must be at least six tabulators, with the fifth field (the source segment, located between the fourth and the fifth tabulator) made of at least one printable character.
The date's first character (a number from 0 to 9, usually, a number 2 if the TU was created in the current millenium) can be "x". It means that this TU is not valid anymore - WFC marked it for future deletion. The first full reorganisation of the TM by WFC will erase this TU. Do not remove the "x", or replace it with a number, unless you know what you are doing.
Placeholders are used to encapsulate a few special characters, or tags. A WFC placeholder always has the following format: &tX; where X can take various values: &t=; &tA; &t1; &t#; , etc.
Note to engineers
The ampersand, quotes, as well as < and > characters are not escaping character.
Those characters are not escaped. The WFC TM format is not a member of the SGML/HTML/XML family.
The WFC TM format is simple text, tab-delimited.
Limitation: A WFC TM would create a slightly fuzzy match with text containing a literal &tX;, as in this very paragraph. That is a known and accepted minor limitation that has not happened yet in decades. That will not halt operation, and creates no problem other than slightly reducing the match score in a negligible number of situations. This is what makes the WFC TM format, created in 1999 and never changed, the fastest, most compact, user-friendly, TM format.
For example, the following "tagged" source segment:
<FONT FACE="Helvetica">This is some text.</FONT>
would appear, in a WFC TM as:
&tA;This is some text.&tB;
At translation time, when WFC pulls a TU from the TM and is about to propose the TU's target segment as a translation candidate, WFC uses a substitution algorithm to dress the proposed target segment with the full "real" tags, taken from the document's (not the TM's) source segment, using a triangulation method:
Document's source segment <-> TM's source segment <-> TM's target segment
The triangulation can be successful only if all target tags have a "parent" tag in the source segment. In the rare cases when the TM's target segment has tags that do not appear in the TM's source segment (orphaned tags), WFC records the full syntax of these orphaned tags at TU creation time, so that they can be restored properly at translation time, when the target segment must be proposed with the correct format. If we have, at TU creation time, the following source text:
&tA;Here is some text:
and assuming the French translation inserts a non-breaking HTML space before the colon, the target segment would be recorded in the TM as:
&tA;Voici du texte&t= \;;:
where &t= opens the original tag syntax ( in our example) and ; (semicolon) closes the sequence. In this exceptional case, the semicolon inside the tag is escaped.
Other examples of segments:
| In target segment: | <AR>Voici du texte<FT> ici. |
| In TM TU source: | &tA;This is some text&tB; here&tA;. |
| In TM TU target: | &tB;Voici du texte&tA; ici. |
| In source segment: | <FT>This is some text<AR> here. |
| In target segment: | <AR>Voici du<AR> texte |
| In TM TU source: | &tA;This is some text&tB; here. |
| In TM TU target: | &tB;Voici du&tB; texte&t= |
In most translation memory systems, TMs are overloaded with tags that do not belong there. A TM takes significance when its content is put to (re-) use, meaning, when its past translations are leveraged for a new transation project. Re-using TM content is only done in the presence of a new document to be translated. The software then operates a triangulation between a new document's new source segment which contains the new formatting, and an existing TM source/target pair which contain tentative formatting placeholders for the previous formatting.
WFC observes rare exceptions, such as hyperlinks, for which the original tag carries the complete information.
Furthermore, tags have real significance inside of one particular project where formatting should be consistent across all documents. But when a TM is applied to a different and new project, most formatting is obsolete. However, most tools keep the bloat and even make it worse from project to project. As a result, the productivity gains of CAT tools can be offset by the enormous bloat created not just by XML-based containers, to which tag bloat is added. An XML-based TM file carrying tags for years can be 10 to 50 times larger than a WFC text-based TM, but the real long-term gain is negligible.
I installed WFC but I don't see the toolbar
Press Ctrl+Alt+W or Alt+Enter.
If no document is open, open a document.
Some, or all shortcuts, do not respond any more
The major causes are:
If you tried all methods described above and shortcuts are not functional, exit Ms-Word, search for, then rename all Normal.dot files to Normal.old and restart Ms-Word.
Multiple keyboards
Some translators have multiple keyboards. Usually, the current keyboard language code is visible in the taskbar like this: EN , and the system uses an Alt combination to toggle keyboards.
If that is the case, in Windows, use the Control panel, then "Keyboard", then look at the shortcuts used to change keyboard: turn them off (this is recommended since keyboards are better changed with the mouse, willingly) or adapt them. Keyboard-changing shortcuts that work in combination with the Alt key interfere with WFC.
You can also right-click the EN icon in the taskbar, choose "Properties" to access keyboard settings and disable the Alt-based shortcuts.
On some systems, this setting could be in the Control Panel's "Regional options".
With Ms-Word 2002 or 2003, the first key I type when a segment opens does not respond
See the FirstKeyControl command in Pandora's Box section.
Ms-Word prompts me to "Save Normal.dot(m)" on a Windows system
Wordfast Classic 9.xx does not modify Normal.dotm (some viruses do, but hopefully your system is protected).
Wordfast Classic 6.xx was adding a macro, but only once, at installation time.
If you see a message prompting to save Normal.dotm, click 'No' at all times.
It's possible, but rare, that Normal.dotm gets "corrupted", with, or without Wordfast Classic installed.
The solution is to close Microsoft Word, use the Windows File Explorer, and do a global search on your hard disk for Normal.dotm.
Then delete all files named "Normal.dotm". Restart Microsoft Word. A brand new Normal.dotm will be re-created.
If you cannot access a Word file because it's locked by another process, there is a possibility that there is a "ghost instance" of Microsoft Word.
Those are created when Microsoft Word crashes, under certain circumstances.
The best way to verify in Windows is to close Word, then press Ctrl+Alt+Delete to start the Task Manager, and look for an instance Microsoft Word. If found, it's a ghost instance. Deleting it will free the document. Ghost instances of Word can be created when there is a crash, which is frequent when normal.dotm is corrupted. Resetting normal.dotm as explained above solves the problem.
Another issue can be a Word Add-on that misbehaves. Those can be PDF converters, dictation add-on, other translation tools, etc. To make sure another add-on is not in cause, simply disable it for some time, to see whether the problem is solved.
My Antivirus says WFC is, or contains, a virus
With over 40,000 installations worldwide, we would be immmediately alerted if that was the case.
Wordfast Classic is constantly sweeped for viruses. Furthermore, it is digitally encrypted using a Wordfast LLC certificate.
Some anti-virus wrongly report Wordfast Classic as a virus. The problem lies on the AV's shallow or mistaken virus detection.
Some AV systems simply report all macro-based programs as viruses without looking deeper.
You can report that to your Anti virus provider. Feel free to send them a copy of wordfast.dot, or point them to our www.wordfast.com, so they can address the issue.
If they don't bother to answer, it's time to look for another AV.
Bottom line: from the year 2020 onward, use your Operating System's default AV.
Microsoft Outlook
Some versions of Outlook can be a problem if they are set to use Ms-Word as email editor. If this is the case, uncheck the "Protect delimiters..." checkbox in WFC/Setup/Segments. Then, in Ms-Word, use View/Toolbars/Customize/Keyboard/Reset all to reset shortcuts. Close Ms-Word and Outlook and try again. If this does not solve the problem, you may have to either not use WFC and Outlook at the same time, or use Outlook's HTML-mode edition (not Ms-Word as an email editor), which offers most of the facilities provided by Ms-Word.
The main WFC setup window does not display any text
Make sure the Tahoma font is available in your system. Normally, when Ms-Word is installed, the Tahoma font is automatically added to your system by Microsoft.
I see lots of blue, or red, text with a line through in the middle
Turn off the revision ("Track changes") mode. Remove the protection, if there is one (Tools/Remove protection) before translation. Normally, documents in revision or "Track changes" mode should not be translated with a CAT tool until this mode is turned off.
WFC (not Ms-Word) says "Sorry, this file is read-only"
This means your translation memory (not your document) has a read-only attribute. This usually happens if the TM was intentionally read-protected, or if the TM comes from a CD-ROM, or from the internet. With your disc explorer, right-click the file, click Property (with a Mac, use Option+i) and uncheck the read-only checkbox.
Also, on some recent systems, certain folders are write-protected. Make sure your TM is not located in an Ms-Office folder, or in any system folder. Create a folder for translation memories.
Do not confuse this message with Ms-Word warning you that a document is in read-only mode.
Erratic behaviour during translation sessions
Some Pandora's box commands need to be turned off after use, like "BetterMatch=Write", "Skip" commands etc, because they may produce unwanted results on documents other than the ones for which they were set. The same consideration applies to macros: turn them off when they're no longer needed. If you never used Pandora's box commands however, there is no need to check this point.
Remember that some options set in Tools/Options and Tools/Autocorrect may also cause erratic behaviour (such as replacing quotes, changing text automatically etc).
Make sure some of WFC's shortcuts are not hijacked by another template.
The first key typed when a segment opens does not respond.
See the FirstKeyControl command in Pandora's Box section.
My keyboard keeps changing
See the point on multiple keyboards.
Make sure you are not on "Automatic language recognition". This option can create problems and make Ms-Word "panic" during translation. Use Ms-Word's Tools/Language menu to make sure.
Ms-Word does not look the same
Or, "After a translation session, Ms-Word displays paragraph marks or field codes or a strange font, or pictures are not displayed etc."
During translation, WFC has to modify some display options in order to function properly. When a translation session ends, your previous display setup should normally be restored. If this is not the case, don't panic - just click Ms-Word's Tools menu, then Options (Edit/Preferences in some Mac versions), click the View tab and check/uncheck the necessary options to restore your usual display setup. Get acquainted with the "Options" dialog box and the various View settings.
You may also have to use Ms-Word's View menu and change from/into the "Page" view.
Ill-behaved documents
Some customers send documents that were originally attached to a template (this can be checked by opening the document, then using the Tools/Templates & Add-Ins menu and looking at the top textbox). If a reference is made to a template that is not present in your hard disc, expect trouble. Contact your customer. Deleting the reference to a non-existent template will usually solve the problem, but should be done with the customer's consent and knowledge, so that the template attachment can later be restored.
If the Ms-Word document has many fields (Tools/Options/View/Field codes or Alt+F9 can be used to display field codes) that refer to non-existent graphics, indexes, links etc, you can have erratic document behaviour. If your customer cannot provide you with the referenced objects, make sure that Tools/Options/General does not require Ms-Word to update links when opening the document.
Large RTF files with complex layout and/or fields, which were created with a different software, or even with just another version of Ms-Word, can behave strangely and cause Ms-Word to crash. In desperate cases, try importing a problem document into a new, empty document, (using copy-paste or Insert/file), with the client's consent.
Always inform the client if you have to fiddle with documents.
The bottom line is that the customer should provide the translator with a clean, stable document. A good third of service calls to the WFC hotline are actually caused by ill-behaved documents, and another third to systems, or Ms-Word installations, that are not stable.
Ill-behaved templates
You are welcome to run WFC together with other templates or Ms-Word add-ins, but please understand that I cannot guarantee the reliability of such a practice. A lot of shortcut conflicts or mysterious behaviours with Ms-Word and WFC are simply due to the presence of other templates or Ms-Word add-ins that monopolise shortcuts.
Ms-Word templates and add-ins are programs that usually contain VBA code. There are many ways of writing VBA, some of which are not really professional, resulting in poorly engineered applications.
Microsoft has introduced a much more reliable and modern environment with the 32-bit VBA architecture of Word97 and higher versions. Unfortunately, many programmers still use antiquated techniques dating back to Ms-Dos (8-bit architecture), or Windows 3 (16-bit architecture) using, for example, absolute I/O file numbers, instead of using the FreeFile function offered by Microsoft, or WORDBASIC functions.
A document was closed with an open segment:
Normally, press Alt+Enter, and WFC will atempt to recover the segment, and usually can do it.
Try starting a session by opening the segment that was left opened. If this does not solve the problem, close the document without saving it, go to the segment that was left opened and do the following:
Open the Bookmark dialog box from the Insert menu. Delete all bookmarks that begin with Wf (such as WfTU, WfSource, WfTarget etc).
Delete all paragraph marks within the problem segment. As a result, the colored backgrounds disappear. If they don't, select the paragraph then use Ctrl-Q or Format/Borders and shadings to remove backgrounds.
Make sure the delimiters (the little purple symbols) are correctly set.
Save your document and resume the translation session.
I want to service my TM, but I keep getting the message "This file is used by another process".
Most likely, the TM is currently opened in Ms-Excel. Or it is being shared through a network, or in two simultaneous Ms-Word sessions, or the previous translation session was not terminated properly. Do not service a TM currently used across a network. If you're not networking, close Ms-Word. With your disc Explorer, find the folder where the translation memory is, and delete the translation memory file that has the ".net" extension - and only this file. If this does not work, reboot your system.
Terminology recognition does not work:
Run the following checklist:
Slow performance or frequent "Out of memory":
Many systems are overloaded with fonts.
Many applications add unwanted fonts to your system without telling you. In Windows, see the \Windows\Fonts (or \Winnt\Fonts) folder.
If you have more than 50 fonts, consider the following. Create a \Windows\Font2 folder and drag-drop into this new folder all the fonts that are found in \Windows\Fonts and that are not vital.
If these fonts are later required, you can drag them back into the \Windows\Fonts (or \WinNt\Fonts) folder.
Note that any font that is located in the \Windows\Font folder burdens your system, gobbling RAM and resources.
There are many other ways to make sure your system is streamlined for optimal professional use, but this is beyond the scope of this manual.
In any case, if your system is used for games, or intensive multimedia activities, or other purposes, especially by other people, expect trouble.
One cannot use a workstation for gaming, or heavy graphical/multimedia applications, and expect it to be utterly stable with the full Microsoft Office environment.
On slower computers (less than 200 MHz and/or less than 32 Mb RAM, and/or very slow video cards), I recommend using some or all of the following methods:
Turn off spell/grammar check during the translation session (make spell-check an after-translation task).
Decrease the color depth of your display to 16 or 256 colors, at least during translation sessions.
Using Tools/Options, uncheck the "Paginate" option to prevent Ms-Word from constantly re-paginating your document. Work in Normal view mode, not Page or Print view.
Turn off the "Autosave" function in Tools/Options or Preferences. During translation, press Ctrl+S once in a while to save your document.
In extreme cases, use the Draft font option in the View tab of the Tools/Options menu in Ms-Word; in the View menu, select Normal rather than Page.
With large TMs (over 50,000 TUs), reorganise the TM at least once a week with the Reorganise button in WFC/Translation memories/TM. Do some TM maintenance.
Uncheck "Allow fast save" in Tools/Options/Save (or "Preferences" in a Mac). "Allow fast save" is known to drain resources and may cause Word to crash.
Desperate cases: pre-translate (WFC/Tools/Tools/Translate) the document before working on it.
Bugs and Crashes
(written in 2002).
Windows 9.xx, Millenium (and 2000 to some extent), as well as Mac OS 7, 8, 9, are not "mission-critical", or bullet-proof OSs like Unix or Linux, for example. They're variations of earlier OSs that were running with late-XXth-century limited resources, over a rather primitive architecture.
All applications, but especially Ms-Word, keep robbing more RAM resources to display fonts, graphics, temporary text editing, undo information, etc. as you open documents, scroll, type, edit, etc. Furthermore, Ms-Word does many tasks in the background, while those OSs are not really multi-tasking.
If Ms-Word crashes while WFC is active: re-start your system and try the same task again with a "fresh" system. Temporarily turn off fancy system add-ons that are supposed to miraculously guard your system from crashes, boost power, enhance the desktop, defragment in the background etc. Just keep the antivirus, but temporarily turn it off for testing purposes. In Ms-Word, turn off any template or add-in other than WFC (go to Tools/Templates & Add-Ins, uncheck templates and add-ins). If you can duplicate the same crash (or freezing) on a bare system, WFC may be the cause of the crash. In case of freezing, try pressing Ctrl+Pause (or Ctrl+Break on some keyboards), then click End if a dialog box appears. If you have the chance, try executing the same job or task with WFC on another computer before concluding that WFC is responsible for the crash.
In such a case, make sure you have the latest version of WFC (compare your version with the one in www.wordfast.net). If the crash persists with the latest version of WFC, use the hotline on www.wordfast.net to let us know. We will process the report as quickly as possible.
The Windows 2000+Ms-Word 2000 (or higher versions) combination is known to be significantly more stable.
WFC refuses to start
This could be due to one of the following reasons:
MacIntosh
Use simple folder and file names for TMs and glossaries, without accented letters, spaces, punctuation, or symbols, less than 32 characters in length. This point does not concern documents, only TMs and glossaries.
(Terms that are already part of the Ms-Word environment are treated briefly - Refer to Ms-Word's Help or Manual for a more complete definition)
CAT: CAT stands for Computer-Assisted Translation. CAT broadly refers to software used by professional translators to boost productivity, and/or enjoy a more comfortable environment. Other acronyms have been added, which only create confusion. In the end, no acronym or naming is ever perfect, and CAT remains the most widely used term.
TMX: TMX stands for Translation Memory eXchange. TMX is a gateway format that allows translation tools to exchange TM content. Most Computer-Assisted Translation (CAT) tools do not use TMX as their native format, but nearly all of them can import from, or export to, the TMX format. As in all conversions, a minor quantity of information may be lost, such as attributes (meta tags).
XLIFF, TTX, TXML: Those are formats made to hold document content during the CAT process. Thus, filters have to used ahead of translation to transform a document (DOC, XLS, PDF, HTML, whatever) into one of those formats; when the translation and proofreading is complete, the same filter must be used to reconstruct the translated document into its original format. Those formats are usually written in XML.
Translation Unit (TU): A TU is a set of source and target segments. A TU also records creation date, plus optional attributes (see below).
Translation Memory (TM): A TM is a set of TUs - a database of TUs. Practically every translation tool has its own format. WFC has its own format but, unlike most other tools, it's an open format, which can be edited with a wide variety of editors. The TMX translation memory format is a gateway between different TM formats. WFC supports TMX.
Attributes: (aka metatags in translation units) A TU is a pair of source and target sentences. TUs have built-in attributes that record information (creation date, languages codes, etc.). 5 user-definable attributes can be customized. A typical attribute is the identity of the translator who generated the TU. Other attributes can be subject, client, job number, etc. Each of the 5 attributes can have many values, stored in a drop-down list, visible in the WFC/Translation memory/TM Attributes tab. For example, the "Subject" attribute could have three possible values, such as "Scientific", "Literary" and "Business". The value that is visible in the drop-down list is said to be the "active" value.
Attributes can help organizing TMs. See the Attributes section for more information.
Match: One purpose of a translation tool is to find "matches" in the TM for the source segment you are curently translating. When a fuzzy match is found, the segment will display a percentage rating the match's resemblance with the TMs reference source segment. Bear in mind that this is a purely statistical and blind computational process, it has little to no semantic relevance. Some CAT tools evoke "semantic" neural networks or "linguistic" sense - those claims are as reliable as washing powder hype.
Penalty: When a match value is being calculated, penalties can be applied to lower the match value. Usually, these penalties are based on an attribute variance. See the relevant section on penalties.
Microsoft Word (Ms-Word): Ms-Word is generally used at a fraction of its capacities. A professional translator will gain a lot by learning a few advanced functions, such as smart Find-Replaces (see the Appendix IV below), customizing toolbars and shortcuts, and essential macro knowledge. Consider seeking expert help or training: this investment in time or money will be recouped very quickly. I have created a step-by-step manual called "Ms-Word for translators" that you can use for free.
Microsoft Office: a collection of applications, usually sold and installed together, of which Ms-Word is a member. Ms-Office includes Ms-Word, Excel, PowerPoint, Access, FrontPage, Publisher, Outlook, OneNote, etc, although the restricted version of Ms-Office usually offers only Ms-Word and Excel.
VBA (Visual Basic for Applications) is a programming language shared by all Ms-Office applications. WFC is written in pure, original VBA, add-ons, OCX, etc. - this is why it runs on both Windows and Mac, and is ready to be ported to other platforms.
Macro. An intensive use of Ms-Word can sometimes lead to highly repetitive tasks (imagine you have to change the first paragraph font on a hundred documents). The macro recorder can record a series of actions done in Ms-Word into a macro named by you; from then on, you can execute this macro as many times as necessary by simply calling the macro dialog box (Alt+F8) and executing the macro, or better, by assigning the macro a shortcut. Macros are written in VBA. Press Alt+F11 or use Tools/Macro/Visual Basic Editor to open the VBA editor window, where your recorded macros will appear, in the code module(s) of your "Normal" template.
Macrovirus (or Ms-Word virus). Any piece of executable code, in practically any language, is a potential virus. The only difference between an application and a virus is the fact that a virus was created to hurt, harm or destroy. Both Ms-Word documents and Ms-Word templates can contain VBA code, as well as many other formats, like graphics etc.
Most operating systems released after 2010 have a built-in virus protection, and do very well without an antivirus. Many antivirus programs place an immense burden on the system and end up being worse than the ill they are supposed to cure.
Every release of WFC is scanned before being put on download. As of September 2019, over 35,000 registered users are using WFC, over 6,000 of them contribute daily to a public discussion group.
If your Antivirus reports that WFC is a virus. This happens with roughly one antivirus in 20. WFC holds lots of VBA code and antivirus applications with a shallow or unreliable virus-detection algorithm can falsely report WFC as virus. You should do any, or all, of the following:
Immediately test WFC with another antivirus - perhaps by asking a colleague equipped with a different brand of antivirus. If another antivirus of another brand also reports WFC a virus, then the matter is serious: WFC has perhaps been infected by an infected document or template. Kindly report this to sales@wordfast.net.
Contact the maker of your antivirus, report the alarm, ask them to download WFC as you have done, so they can also test it. Then they should (if they are serious and honest) modify their antivirus software, or prove that WFC is a virus - one of the two.
Contact the WFC hotline at info@wordfast.net. No need to post panicking mails in the mailing list: all such mails until now were proved to be false alarms, and an embarrassment for their authors.
Documents and Templates: A document holds contents, i.e., text.
A Template is a model of document that proposes a preset layout, so that the user can concentrate on contents rather than on appearance. Templates can also be used as Add-Ins, extending Ms-Word's capacities. WFC is an Add-In.
Normally, a template is not opened as a document: it is either used to create new documents with a certain preset appearance, or it is added to Ms-Word's list of templates, using the Tools/Templates & Add-Ins menu. WFC belongs to this last category.
Toolbars: (this is for Ms-Word versions prior to Ms-Word 2007. From Ms-Word 2007 onward, toolbars are contained in a so-called Ribbon, which can be either minimized (Ctrl+F1), or occupy substantial screen real-estate.)
Ms-Word's "View" menu has a "Toolbars" option (right-click in the toolbar area to get there quickly) that lets you turn toolbars off and on. Turn off toolbars you are not using: they take up space and load the visual field, creating confusion. Use the same menu's "Customise" option to customise toolbars.
In the "Customise" dialog box, go to the "Commands" tab (the second one). Experiment by clicking in the list of commands, holding the button down, dragging a command. Drop its icon in a toolbar of your choice. You have just added a icon to your toolbar. If you make intensive use of a Ms-Word function and keep using menus, it is recommended to drop the corresponding command in a toolbar for quick access.
To remove an icon from a toolbar (the "Customise" dialog box being visible), drag its icon and drop it outside the toolbar: it will be removed.
I encourage WFC users to add the following two icons in either the "Standard" or the "Formatting" toolbar: Format/PasteFormat (play with it to learn how powerful it is. The icon looks like a brush, or a short broomstick); View/FieldCodes. Do not customise WFC's toolbars.
Selection: Dragging the mouse over text in a document while holding the left button (Windows) or the single button (Mac) will select a portion of the document, which then appears in reverse video, usually white on black. The insertion point (the blinking cursor) disappears when a selection is made. A selection can also be made by holding either Shift key down and moving the cursor by means of the arrow keys.
When a selection is cancelled, the insertion point, or cursor, appears again.
Bookmarks: A bookmark, as in a paper book, is inserted at some position in the document so that we can get back there quickly at a later time. Use the Insert menu to insert a bookmark over the current selection, or at the insertion point. The bookmark has to be given a name. The bookmark will "remember" the selection's position and extent in the document.
Bookmarks are saved together with a document.
Ms-Word's Tools/Options/View dialog box can be used to have the position and span of bookmarks made visible with grey [brackets].
Bookmarks are part of the document, and play a crucial role in documents that have links, automatic indexes, table of contents etc. The translation process may require bookmarks to be transferred into the translated text, at the appropriate position, extending over a corresponding length of text, retaining the same bookmark name. Since two bookmarks cannot have the same name in the same document, WFC proposes ways to handle them during the translation process. Refer to the Bookmarks section.
Refer to Ms-Word's Help or Manual for more information on bookmarks.
Fields: Fields can be inserted into a document using the Insert/Field... menu. A field usually contains a code that has to be calculated, computed or in some way, processed by Ms-Word. Thus, there are two ways of looking at fields: the code, or the result. Use Tools/Options/View to toggle field display modes, or use the Alt+F9 shortcut.
Note that fields are calculated at the moment when they were created. Placing the cursor over a field and pressing F9 will force the update (the recalculation) of the field.
A field that has not been updated may perhaps not show a correct value. For example, a Table of Contents, which is produced by a TOC field, may not necessarily be up-to-date.
If the update produces an error, the field will display an error message.
Refer to Ms-Word's Help or Manual for more information on fields.
Tags: See the section on Tags for a thorough presentation of tags. This term refers only to special untranslatable elements (usually grey or red) found in a particular category of files known as "tagged files", pre-processed for translation with adequate software (Rainbow Horizon, PlusTools, Trados Stagger, etc).
Delimiters (segment delimiters): Those should not be confused with tags. Delimiters are the purple symbols that delimit the beginning and end of both source and target segments, such as {0> .
A bad segment is a segment where delimiters have suffered from deletion, addition, or edition. Bad segments create problems at cleanup time. They can be manually fixed by reproducing the set of delimiters found in a healthy segment.
Segment: A segment is an elementary unit of translation. Segments are usually sentences. In some cases, it may be necessary to translate entire paragraphs rather than sentences, but this is rarely the case.
During a translation session, the current segment (with the colored background for source and target segments) is said to be opened. Segments should be left opened only for the duration of the translation process. If you need to make a break, complete your current segment then press Alt+End to close both the segment and the translation session.
Commit a segment: A segment is committed when the translator presses Alt+Enter or Alt+End on an opened segment during a translation session, thereby "closing" the currently opened segment. At that moment, if the source/target pair does not exist in the TM, the pair of sentences will be added to the TM (subject to TM rules). Shift+Alt+End (Close segment) will close a segment without committing it to the TM.
Source, target: Translation is done from a source language (in)to a target language. A translation project may have one source language and many target languages. Most translators, however, deal with one source language and one target language, in which case, we speak of a language pair.
WFC considers a document as a set of segments, a segment usually being a sentence, ending with an end-of-segment punctuation (ESP) such as full stop, question mark etc. (the ESPs are customizable in WFC's Setup/General tab). Paragraph marks, page breaks, end of cell, tabulators etc will always end a segment. I have highlighted the 10 segments present in the following example:
The mark-ups for retail are as follows: for class A stores, 10%. For class B stores, 15%. Please observe the following chart:
Class Class A Class B Mark-up. No exceptions 10% 15%
These mark-ups must be applied at all times.
Note that the isolated 10% and 15% are not considered segments. A segment must have at least one translatable item (at least one letter). See the segment example. It is possible, however, to force WFC to segment such untranslatable text: see Pandora's box SegmentAll command.
Even in the absence of translation memory, a segmenter saves time and boosts productivity. The problems, when translating from a printed document, are:
Eye strain.
You will constantly move back and forth between the paper document and the computer screen. Your eyes will have to re-focus many times every minute. A lot of translators end up, after a number of years, with severe sight problems.
Brain strain.
After having translated a sentence, you will have to look again at your paper sheet and locate the exact position of the last sentence and read the next one. This exercise requires attention and drains intellectual power.
Professional errors.
Because of problem 2, it regularly happens that we skip a sentence, not to mention an entire paragraph, which is a serious professional error. Perhaps the document is made of a series of 100 nearly identical sentences, with slightly different numerical parameters, like
Please apply the following mark-up for Class A: 10% Please apply the following mark-up for Class B: 12% but exclude zone TT-001 Please apply the following mark-up for Class C: 11.5% Please apply the following mark-up for Class F: 13% Please apply the following mark-up for Class P: 9%
...etc for 3 pages!
If one line is forgotten, the translator becomes responsible for a serious professional error.
Working with a segmenter on an electronic original, you will not have to worry a second. The segmenter will faithfully segment the document and ask you to translate every segment, without forgetting a drop. Furthermore, in the above example, once you have translated the first line, WFC will actually recognise the next lines and pre-translate them for you.
More professional errors.
Look at the second line, with the TT-001 parameter. This parameter should not be translated, but faithfully copied. Now, make sure you type Zero-Zero-One and not O-O-I. Seems easy? Technical documents are full of such Byzantine parameters. To us, they're annoying. To the customer, they're vital. Mis-type just one, and the customer ends up with a faulty manual.
WFC has a Quality Assurance algorithm that will warn you if the untranslatable parameters are not faithfully copied from source to target. It also has QA functions to help respect the customer's specs on typography.
Document layout.
Look again at the above example on segmentation. If you translate from paper, you will have to re-create that fancy layout, fiddling with formats, tables, borders, colors, fonts etc. With WFC, every target segment is formatted like the source segment (this is true at segment level, the first source character defining the format of the target segment. WFC makes every effort to duplicate the styles of, for example, untranslatable elements; in somes cases, you may have to manually apply bold, italic etc within the segment).
Terminology consistency.
Over a large project (say you receive 50 pages every month, so you work for this particular customer 5 days a month, for 12 months), every time you work, you will have to remember the customer's glossary. With WFC, you create and save a particular setup for each customer, which remembers TM and glossaries. WFC will warn you every time the translation's terminology is in conflict with the customer's glossary.
The natural complement of a segmenter is translation memory. Every time a segment is translated, it is stored in the TM. Thus, a TM is a database of Translation Units (TU). A TU records source & target segments, date of creation, languages used, and the ID of the TU's creator. It also has a usage counter that records how many times a TU was re-used. The more a TU is re-used, the more it is valuable.
Translation memory, mostly on technical documents, can save a lot of time, because WFC will recognise segments that were already translated and propose them - you only have to check, validate and move on.
When WFC has delimited a segment, it will scan the TM, searching for an exact or approximate match to the source segment. If a match is found, the TU's target segment (the recorded translation) is proposed. WFC will display a number, ranging from 0 to 100, that rates the degree of similarity between the document's source segment and the TU's source segment. A 100% match is considered exact. A match under 100% but equal to or above the (user-definable) fuzzy threshold is considered fuzzy; beneath that value, it is considered a no-match and will not be proposed.
If a translation is proposed, pressing Ctrl+Alt+M (Memory) will display the TU that was found during the TM's scan. In the case of a fuzzy match, differences between the document's source segment and the TU's source segment are highlighted. The TM management section contains valuable supplementary information.
If WFC has found many matches, pressing Alt+Right/Left will display matches with lower/greater match value.
A document can contain text written in different languages. In Ms-Word, the language is a text attribute, just as font, color, etc. In Word, the "Set Language" dialog box is used to apply a certain language to a selection of text. This dialog box is called as follows:
WFC will apply the specified target language (or default language, as specified in WFC/Setup/Segments) to the target segment. If, however, you have chosen the "leave unchanged" setting, WFC will not redefine the target language.
About all macros entered with Pandora's Box "Macro..." commands
(PC only): if instead of a macro name, you enter "Keys=" followed by a string of text similar to the one described in the Dictionary keys section, then WFC will execute the keystrokes you have defined. For example, using
Keys=L&H;^a{Delete}{SourceSegment}{Home}%tt{Ms-Word}
in conjunction with the English version of L&H's Power Translator 7 text-to-speech function, will read aloud your source segment at the time it is presented for translation.
Creating macros
Macros should normally be entered in Normal.dot. To do so: in Ms-Word, use Tools/Macro/Visual basic editor (or press Alt+F11) to open the VBA window. In the left side of the window, double-click "Normal". If there is no module, use the Insert menu to add a module. Usually, a new module called "Module1" is added. Double-click it. A window should open to the right: this is where you should copy-paste the macros given below, and edit them as needed. These macros will be saved with Normal.dot when you exit Ms-Word.
The WFC hotline does not offer support on VBA and macros. Refer to your Ms-Word manual, or to literature on the subject.
In WFC/PB/Macro..., you should enter "Normal.Module1.CheckLength" if, for example, you want to try the first macro described below (either as a QA macro, or as a post-segmentation macro).
To associate a macro with a shortcut: use the View/Toolbars/Customise menu. Click "Keyboard". In the leftmost list, choose "Macros" as category. In the righmost list, click the macro name. Enter the Shortcut in the textbox, then click "Assign". Close the dialog box.
You should refrain from using the following statements or instructions in macros you intend to use with WFC
If you need to open and close I/O files on disk, remember to use the FreeFile() function to ask VBA for an available I/O file number. Otherwise, your macro may conflict with a file already in use by WFC.
If you want your QA or post-segmentation macro to refuse to validate the segment and prompt the user to correct the translation, your macro should add a "WfStop" bookmark anywhere in the document (simply insert a Selection.Bookmarks.Add "WfStop" instruction before ending the macro). If WFC finds such a bookmark, it will cancel segment validation, remove the bookmark and take the user back to the target segment.
Here is a typical QA macro using the interactive mode just described above. It checks the target segment to make sure it's not longer than 80 characters (spaces included). If it is, it warns the user and sends him/her back to the segment:
Sub CheckLength() If Not ActiveDocument.Bookmarks.Exists("WfTarget") Then Exit Sub If Len(ActiveDocument.Bookmarks("WfTarget").Range.Text) > 80 Then If MsgBox("Target > 80 signs! Stop and edit?", vbYesNo, "WFC") = vbYes Then Selection.Bookmarks.Add "WfStop" End If End If End Sub
The following macro does the same as the previous macro, but this time, the visible length of text is compared rather than just the number of characters. Note that a segment's visible length depends on its font.
Sub CheckRealLengthOfText() 'This macro warns the user if the target segment is over 130% of the source's length. 'The *real* visible length of text is compared, not just character count '(Of course we assume both source and target have the same font and size) Dim I As Integer, Segment As Range Static L(1) As Long For I = 0 To 1 If I = 0 Then Set Segment = ActiveDocument.Bookmarks("WfSource").Range Else Set Segment = ActiveDocument.Bookmarks("WfTarget").Range End If Selection.Start = Segment.Start: Selection.End = Selection.Start Do While Selection.Start < Segment.End - 2 Selection.MoveStart wdLine: Selection.MoveEnd , -1 L(I) = L(I) + Selection.Information(wdHorizontalPositionRelativeToTextBoundary) Selection.MoveStart , 1 Loop Next 'Here, "1.3" means 130%. Change this figure as needed. If (L(1) > L(0) * 1.3) Then If MsgBox("Target text length is over 130% that of source target." + vbCr + vbCr + "Get back to the segment and correct it?", vbYesNo, "WFC") = vbYes Then Selection.Bookmarks.Add "WfStop" End If End If End Sub
The following macro compares source/target segment to make sure quotes are consistent (same types and numbers of quotes used). Add this macro to WFC/Setup/General, as a QA macro, or as a Post-segmentation macro.
When a quote discrepancy is found, WFC will warn the user, with a choice of getting back to the segment and correcting the problem, or just moving on to the next segment.
Sub CheckQuotes() If Not ActiveDocument.Bookmarks.Exists("WfSource") Then Exit Sub Dim I As Integer, Src As String, Trg As String, Quotes As String, Uq As String Quotes = Chr(34) + Chr(171) + Chr(187) + Chr(147) + Chr(148) Src = ActiveDocument.Bookmarks("WfSource").Range.Text Trg = ActiveDocument.Bookmarks("WfTarget").Range.Text For I = 1 To Len(Quotes) Uq = Mid(Quotes, I, 1) If (InStr(Src, Uq) > 0 And InStr(Trg, Uq) = 0) Or (InStr(Src, Uq) = 0 And InStr(Trg, Uq) > 0) Then If MsgBox("Possible problem with quotes (" + Uq + ".) Fix it?", vbYesNo, "WFC") = vbYes Then Selection.Bookmarks.Add "WfStop" End If Exit Sub Else If InStr(Src, Uq) > 0 Or InStr(Trg, Uq) > 0 Then If InStr(Src, Uq) > 0 Then Mid(Src, InStr(Src, Uq), 1) = "*" If InStr(Trg, Uq) > 0 Then Mid(Trg, InStr(Trg, Uq), 1) = "*" I = I - 1 End If End If Next End Sub
Q: I would like to highlight selected text, not using highlight, but Borders and Shading/Shade/Yellow instead. However, this is really slow because I have to use the menus each time.
A: Associate the following macro to Alt+H. See the part on associating macros with a shortcut.
Sub HighLight() Selection.Font.Shading.BackgroundPatternColorIndex = wdYellow End Sub
Q: I want to run a word count of all the text contained in textboxes in my document.
A: Run the following macro. It will create a new document containing all text found in textboxes.
Sub ExtractFromTextBoxes() Dim I As Integer, J as Integer, Boite As Variant, ThisDoc As Document ActiveWindow.View.Type = wdPrintView Set ThisDoc = ActiveDocument DocName = ThisDoc.FullName Documents.Add On Local Error Resume Next ' Convert InlineShapes (anchored shapes) to regular shapes For Each Boite In ThisDoc.InlineShapes Boite.ConvertToShape Next ' I > 0 indicates there are still ungrouped textboxes to process ' J is just a security to avoid looping endlessly. I = 1: J = 0 While I > 0 And J < 10000 ' Ungroup grouped shapes For Each Boite In ThisDoc.Shapes Boite.Ungroup Next ' make sure all textboxes were ungrouped ' (embedded groupings may need more than one pass to be ungrouped) For Each Boite In ThisDoc.Shapes I = 0: I = Boite.GroupItems.Count If I > 0 Then Exit For Next J = J + 1 Wend For Each Boite In ThisDoc.Shapes With Boite.TextFrame ' If a textbox has text, copy it into the empty document If .HasText Then Selection.InsertAfter .TextRange Selection.InsertParagraphAfter Selection.Start = Selection.End End If End With Next ' Ungrouping usually creates a mess: ' close the original document without saving it ThisDoc.Close 0 End Sub
Sub TextToDoc() Dim S As Selection, D1 As Range, D2 As Range, IsPara As Boolean, T As String If Windows.Count = 0 Then MsgBox "Sorry, no document open": Exit Sub Set S = ActiveWindow.Selection: Set D1 = S.Range: Set D2 = S.Range S.End = 0 Do While S.Start < S.StoryLength - 1 ' Turn off screen refresh for better speed Application.ScreenUpdating = False IsPara = False ' We store the last letter of the line into the string T S.MoveEndUntil vbCr: T = Trim(S.Text): T = Right(T, 1) ' A first attempt to determine if we do have an end of paragraph: ' the line ends with an end-of-sentence If InStr(".!?", T) > 0 Then IsPara = True If S.End < S.StoryLength - 3 Then D1.SetRange S.End + 1, S.End + 2 If IsPara Then D2.SetRange S.End - 1, S.End Else D2.SetRange S.End - 2, S.End - 1 ' If the last character of the line is lowercase and the first character of the next line is uppercase, ' we'll assume we've got a real paragraph. ' Disable this for languages that capitalize a lot, like German etc. If D2.Characters(1).Case = wdLowerCase And D1.Characters(1).Case = wdUpperCase Then IsPara = True ' if the font name or size varies from the current line to the next, we'll also assume ' there's a new paragraph. Very often the case with text copied from PDF; not ' relevant with Txt files. If S.Font.Name <> D1.Font.Name Then IsPara = True If S.Font.Size <> D1.Font.Size Then IsPara = True End If ' If we do not have a paragraph, then join the two lines into one and move on If Not IsPara Then S.Start = S.End: S.Delete: S.InsertAfter " " Else S.InsertParagraphAfter: S.MoveStart wdParagraph, 1: S.MoveStart wdParagraph, 1 End If Loop S.End = 0 MsgBox "Text to Doc conversion finished. Please check the document." End Sub
Ms-Word's Find/Replace feature (F-R) accepts wildcards and advanced features. A good understanding of F-R can save the day on numerous occasions. I had to oversee translation projects where, to my astonishment, translators were spending hours executing visual/manual Find-Replace actions that could have been safely executed automatically.
Sure, F-R actions can be destructive if they're not executed properly, since they can modify unwanted parts of the document. On a short document, a visual/manual F-R can be preferred, since setting up and testing a smart and safe FR can take a little while.
Note that PlusTools offers an F-R feature that can be run over many files, both in manual and automatic mode, with the possibility to edit the document and restart the F-R where it was interrupted.
Q: Whoops! My documents have been pretranslated, and I don't have access to the originals. But now I would like to have the originals back, unsegmented. Apparently, it takes a lot of successive Find-Replace passes to un-segment documents...
A: Quite the contrary. It takes only one F-R pass to do that.
Find what (\{\0\>)(*)(\<\})(*)(\{\>)(*)(\<\0\}) Replace with \2 Use Wildcards Set the replacement font format to "not hidden" (check, then uncheck, the "Hidden" checkbox).
The only limitation is, make sure source segments do not contain hidden text. But they rarely do.
Note: the the same result can be achieved with the Alt+Delete shortcut, pressed when no segment is opened.
This means changing US thousand separators (commas) into non-breaking spaces, and US decimal separators (full stops) into commas. Here is a two-pass method:
Find what .([0-9][0-9])> Replace with ,\1 Use Wildcards
then,
Find what ([0-9]),([0-9][0-9][0-9]) Replace with \1^s\2 Use Wildcards
This method is offered as sample in WFC's Pandora's box commands. Note that WFC's "FR" command executes F-R actions only in the current target segment, at segment validation time.
Use this F-R in automatic mode ("Replace all") if the figures and numbers in your document are essentially financial. If, however, your document mixes scientific figures with financial figures, I recommend using this F-R method with a visual confirmation for each replacement (in Ms-Word's "Find" dialog box, click "Find Next" and "Replace" rather than "Replace all").
Q: In my document, all lines end with a carriage return, even if they don't end a paragraph. What can I do to reconstruct a normal text flow?
A: There is no absolute answer, but a global F-R can do most of the job; a last manual verification will restore paragraphs that are unduly cut.
Find what ^p^p Replace with <!?a$
The above F-R will preserve double paragraph marks (replacing them into a very unlikeky sequence of characters, which we here call a code)
Find what ^p Replace with
The above F-R will turn all single paragraph marks into a space. A space has to be entered in the "Replace with" argument.
Find what <!?a$ Replace with ^p^p
The above F-R will restore double hard carriage returns.
This is a typical three-pass F-R example. Note that when using wildcards, Ms-Word no longer accepts some characters such as ^p (hard carriage return), so two- or three-pass F-R actions are often necessary to bypass this limitation.
But hey, wait a minute...
Actually, a one-pass FR can achieve just the same result, but don't tell anyone, because it's a secret:
Find what ([!^0013])([^0013])([!^0013]) Replace with \1 \3 Use Wildcards
(Note the space after \1) Amazing, right? Be cautious though. On some Ms-Word versions, ^0013 introduces a new line but not necessarily a new paragraph, as surprising as this may seem. Use this geeky method if you're a geek yourself and know what you're doing.
A segmentation problem had produced segments where match values were often over 100. So the documents had such match values as <}833{> or <}944{> etc. It appeared that the last figure of the match value had been duplicated (these two segments should have been <}83{>.and <}94{>). How could this be fixed in many documents, in one pass, making sure other figures are not modified by the procedure?
The answer is:
Find what (\<\})([1-9])(?)(?)(\{\>) Replace with \1\2\3\5 Use Wildcards
Explanation: When the "Match wildcards" checkbox is checked, "expressions" are anything contained within parentheses. The "Replace with" numbers actually refers to expressions located in the "Find what" argument.
The ([1-9]) expression in the "Find what" argument, for example, refers to any number in the range 1 - 9. In the "Replace with" argument, it is referred to as \1, meaning, "expression 2".
So the Find-Replace action can be read as:
If such a chunk of text is found, replace the entire chunk with expressions 1, 2, 3, 5.
As a result, the redundant number (expression 4) is deleted from match values, with no risk of upsetting the rest of the document. An added safety measure could be to set the style for the Search parameter to "tw4winMark".
Q: I have a segmented document, where the source segment was copied over the target segment when there were no matches (0%). Now I would like the target segments to be empty instead, but of course, leaving fuzzy and exact matches in place, untouched.
A: A find-replace can, in one pass, transform zero matches where the source has been copied to target into no-matches with an empty target.
Find what (\<\}\0\{\>)*(\<\0\}) Replace with \1\2 Use wild cards
Use the View/Toolbars menu, click the customise submenu. Click "Keyboard". In the "Categories" list, click "Macros". Select the macro. Enter the shortcut in the Shorcut text box, then click "Assign" then "Close".
Disclaimer: the following content is offered as practical guidance, and does not constitute medical advice. Please seek qualified medical help if you need.
Ms-Word has a "View" setting that offers, among others, two fundamental modes: "Print" (aka "Page", or WYSIWYG mode), and "Draft" (aka "Normal") view.
Draft is the recommended setting for translation.
If layout and the final look are important, and they usually are, temporarily shift to Page view during proofreading, using "Draft" view for translation.
It is still possible to use the WYSIWYG "Page" view at translation time for short documents (less than ~20 pages) that do not have a rich or complex layout.
WYSIWYG "Page" view generates frequent flicker, due to Ms-Word redrawing the page as you type.
On large or complex documents, constant flicker not only hurts the eyes, it also seriously hampers productivity.
This is why the "Draft" should be used for the translation phase, while "Print" or "Page" mode should be used for the final proofreading/QA stages.
Bottom line: translation is not authoring, "Page", or WYSIWYG view may look beautiful, but may also be false friends.
Draft view is rock stable, is easily zoomed to fit the screen, wastes less space, offering better legibility and focus.
Page view forces Microsoft Word to constantly repaginate in order to draw a graphically correct page. In large and complex documents, Page view with a WFC translation session can exhaust Ms-Word's resources, possibly crashing Ms-Word.
What is an optimal zoom factor?
Ophtalmologists recommend the following standard: from your usual viewing distance (do not get near the screen to perform this),
set your zoom factor to the smallest text you can read, a size where you can just recognize letters (if smaller, text would be impossible to read).
The recommended zoom factor is three times that strong.
On Microsoft Word, or even in a browser, probably right now, keep the Control key pressed and use the mouse wheel. Note the zoom factor (which appears when you move the mouse wheel). On my 21-inch monitor right now, sitting ~ 20 inches (~ 50 cm) away, with text that's a default 10 points, the smallest zoom factor at which I can still read is 50%. Thus, comfortable reading would be achieved at 3 x 50% = 150% zoom. But for some reason, my high-mileage eyes find 130% to be fine. Life is good. I keep my browser at 125%.
Note: we are dealing with a zoom factor (a ratio, expressed in %), not font size (an absolute value). The above discussion assumes text with a 10-point font size. Documents rarely use fonts under 10, or over 12 points, for the document's body. Make the necessary adjustments.
What is an optimal brightness level?
This setting is as important as the proper zoom factor. Too much brightness can permanently hurt the eye.
Too little brightness forces the eye and brain to work more (alas, unconsciously, so we only notice when it's too late) to recognize letters.
The brightness level depends on your immediate environment.
Your monitor should feel like you're looking at a sheet of white paper, with perhaps 10 to 15% more brightness - not more. The way a sheet of white paper reflects light depends on your environment, so only you can decide that. Look at a whitish part of your screen, then ask yourself the question: do I have the impression to stare at a light source? If the answer is yes, brightness may be too high. Slightly reduce brightness level, overcoming that reptilian aversion to change ("Oh no, changing work habits? Never!"). Give a try for over a day. See whether that helps.
Bad habit: not changing brightness level when night arrives, working in a dark office staring at a day-level monitor. Translators on a deadline (rather, always on a deadline?) are night owls. Owls are cute, blind owls are miserable. Check whether your monitor can adapt to ambient light. Mine can, but it seems I don't see the difference, which is normal: you should not feel a difference with a high brightness level day-time, compared to reduced brightness at night.
Keep one or two lights of medium intensity in your office at night - but not in direct view, and avoiding reflection on the screen.
If you work on a laptop, I advise attaching an external monitor and an external keyboard when at home. Using a bare laptop as workhorse is not a good idea. If you don't agree, you're probably still young: Hakuna Matata :-)
External keyboards offer dedicated Home, End, PageUp, PageDown keys, which are crucial to text navigation. Not having those navigation keys really hurts productivity, forcing you to use 2-key shortcuts, or the mouse, all the time.
What is the optimal geometry?
Humans have a total field of view (FOV) of approximately 180% x 180%. But that's for escaping predators, spotting preys, and staying on alert.
However, when reading and paying attention to minute details for long periods of time, a healthy FOV is much more limited.
Eye movement within their orbits should be minimal; head movement should be even more minimal.
Having said that, take frequents breaks for body movements, and neck relief.
The zoom factor is important for productivity. It impacts legibility. A bad zoom factor can dramatically increase errors. Here, comfort means quality.
Before you set it, try to have Word occupy sufficient space on your desktop - without necessarily maximizing Word's window. I do not recommend maximizing Word's window, unless your screen is really small.
In Draft view, adjust the zoom factor to have a comfortable text size. Ideally, there should be a couple lines of text before (atop) and after (beneath) the segment, for context.
This is easy to achieve on a large monitor, but is difficult, and critical, on small or medium-sized laptops.
Once this is done, make sure that text wraps on long sentences, instead of disappearing beyond Word's right border. Note that WFC has a setting under Setup / View to make sure that text wraps. Check that option, even if you don't check Start translation in Draft mode.With tables or textboxes, and other objects, these settings are important. Here are two examples of bad zoom factors (too strong) that will result in constant horizontal scrolling and jitter:
Note in the above examples that zoom factor is closely related to window width. In the first example, widening the window would also solve the issue. But it would be impossible on a small monitor, so zoom factor is crucial on laptops.
Rulers. For us translators, rulers are rarely necessary. Rulers are for authors, who also rarely use them. Turn them off unless you have a good reason to keep them.
Status bar. The status bar, if visible, is at the bottom of the document window. Keep it visible: WFC occasionally uses it for messages. Side panes, anchored or floating. Ms-Word may open various panes, such as the search pane, the "Editor", or spell-check pane, a floating or fixed style pane, etc. Only keep them opened on really large monitors. On a laptop, those must be closed after use with their little "Close" button.WFC shortcuts are better than the mouse - at all times. Memorizing essential shortcuts is essential to productivity - unless you're paid by the hour.
See this chapter for a complete list of shortcuts.
The arch-essential shortcuts are:
| Alt+Enter Alt+Down | Start translation / Next segment |
| Alt+Up | Previous segment |
| Alt+End | Close segment / End translation |
| Alt+S | Copy source Mac: Ctrl+S |
| Alt+Delete | Restore (un-segment) a segment |
| Ctrl+Alt+X | Clear the target segment (delete target text) |
Those are shortcuts you cannot afford to ignore. If you find that you frequently use the mouse for a certain type of action, learn the associated shortcut. Ms-Word and Wordfast Classic have shortcuts for most actions. Want to be convinced? Open two (or more) documents in Ms-Word, play with Ctrl+F6. Need more convincing? On Windows, press Alt+PrintScreen (little PrnScrn key, top right of the keyboard, the Mac has another technique). In an email, press Ctrl+V, (Command+V on a Mac). You've included a screenshot in an email in seconds rather than minutes. Now you can give Ted talks on productivity.
Rambling or hobo translators have to deal with really small screens. WFC tries to accomodate even the smallest devices.
There is a dedicated option under Setup > View for small laptop screens, which keeps segments down to a minimalist view mode without much sacrifice on the feature set.
Use this mode in combination with a shrunk Word ribbon (Ctrl+F1), no rulers, a draft view mode, a proper zoom factor, and you're good to go!
Note: there are options in Wordfast Classic under Setup > View to use lighter shades for an opened segment, or no shades at all. I've done decades of translation on blurry 13-inch passive-matrix displays, last century, and this century. You should be fine with a few precautions. I can still (proof)read a document from a foot away and spot it's typos. Pun intended. A tip for night owls: when the chin hits the spacebar, time to go to bed.
That may also come in handy in strong sunshine, poolside translation, space tourism, or cast away on a desert island.
Laptop with a "very small" LCD screen (11-inch), Ms-Word 2019, shrunk ribbon, no rulers, Draft view, Minimalist segment enabled under Setup > View, toolbar set as Mini:
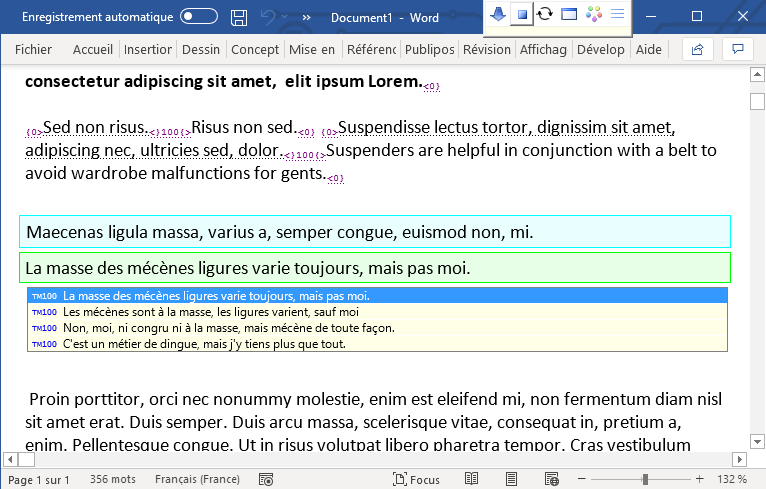
Fragment from a large monitor (21-inch; other applications running on the same monitor), the mighty Ms-Word 2019 with deployed ribbon, complete segment with the TM's detail above it, AutoSuggest underneath, document context above and below - the whole shebang:
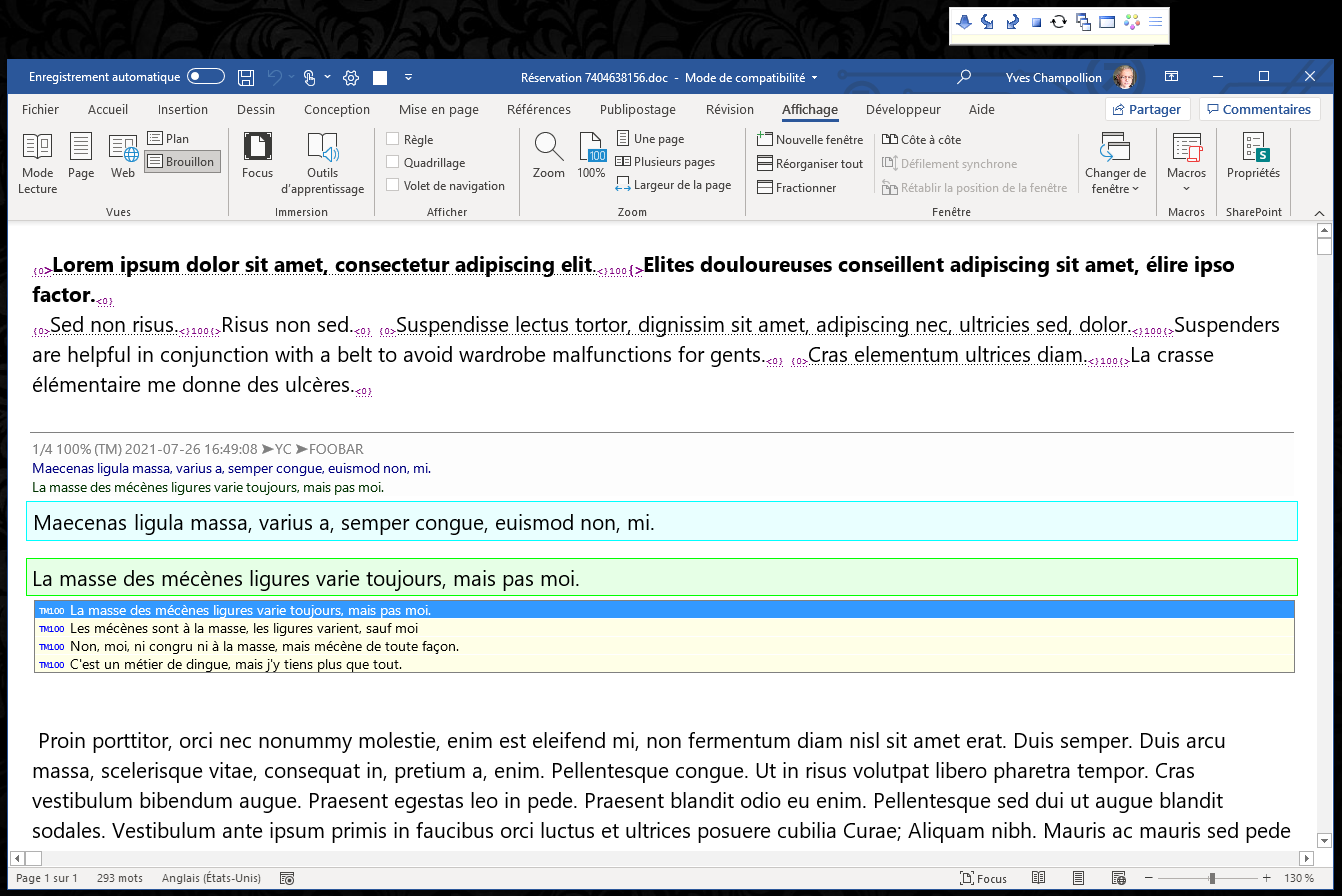
Warning: this concerns Mac Word 2011 (pre-Catalina) and, to a lesser extent, Windows Word 2000, 2002, XP, 2003.
Download the WFC7toolbar.doc document, open it with Ms-Word.
Press F10. This will install the older WFC toolbar in Ms-Word. If this succeeds, you may enable Setup > Pandora's Box and add NewToolbar=No to it.
If the toolbar does not appear, run the following instructions:
All trademarks noted™ are the property of their respective owners.
Ms-Word, Excel, Acces, PowerPoint are trademarks of Microsoft Corp.
Translator's Workbench is a trademark of Trados Corporation